TL;DR Modern MoE Transformers usually give each MoE layer its own private expert pool, so expert parameters grow roughly with the number of MoE layers. UniPool addresses this wasteful layer-local allocation by letting different layers route into a shared global expert pool, reducing expert parameters by up to 60% while maintaining similar performance.
Vanilla MoE: Every Layer Gets Its Own Experts
In a traditional MoE Transformer, each MoE layer has its own isolated set of experts. A router takes the current token representation, scores the available experts, and sends the token to the top-k experts (usually one or two). The selected experts process the hidden state, and their outputs are combined using the routing scores.
This design is simple, but it also creates a rigid scaling rule: every MoE layer owns its own expert capacity. If we add more MoE layers, we usually add more expert parameters.
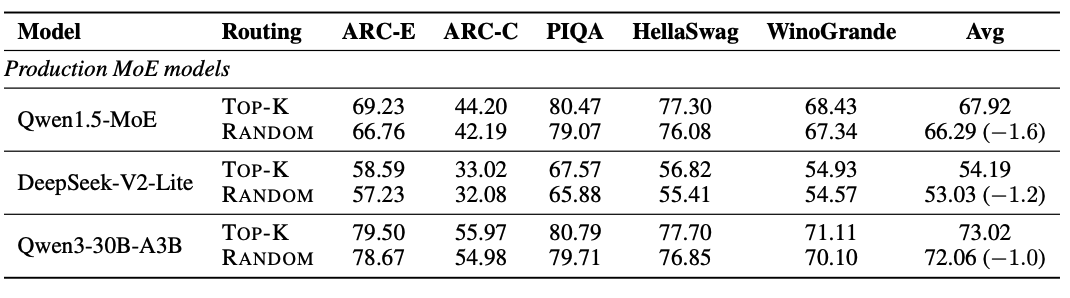
This is the waste UniPool targets. The paper argues that layer-local expert ownership can duplicate capacity. Experts at different depths may learn similar transformations, and the routing probe in the paper suggests that, at least in some deeper MoE layers, replacing the learned router with random routing only hurts downstream accuracy by 1.0-1.6 points. I read this as evidence against rigid per-layer expert allocation, not as evidence that routing is generally unimportant.
UniPool: One Shared Expert Pool Across Layers
UniPool changes the allocation rule. Instead of giving every MoE layer its own private expert pool, it creates one shared pool of experts. Each layer still has its own router, but those routers all select from the same global expert pool.
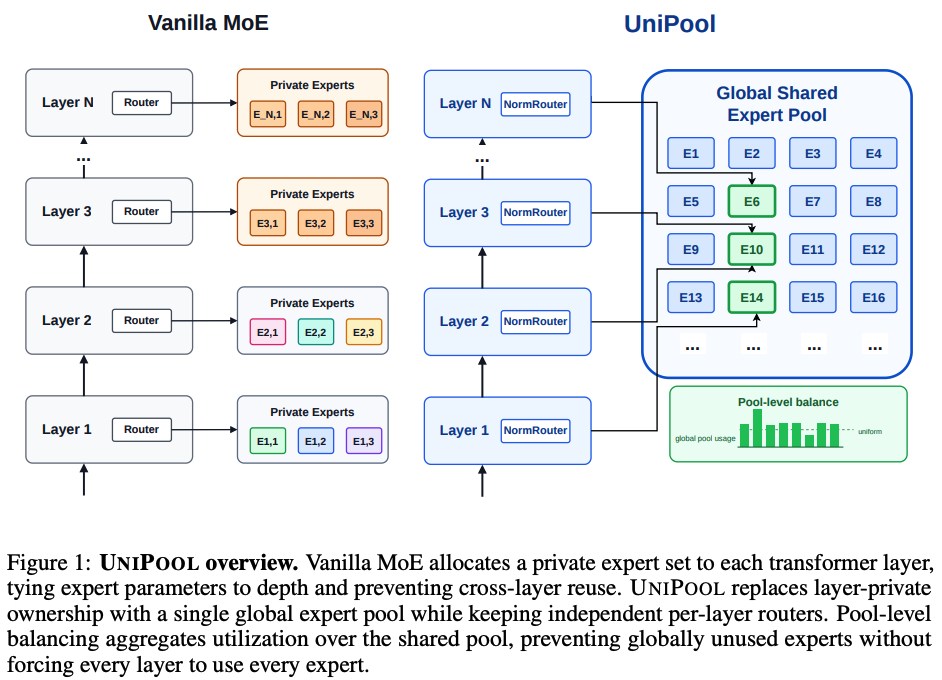
To make this work, the paper adds two main pieces:
- Pool-level auxiliary loss: instead of balancing expert usage independently per layer, UniPool aggregates token-to-expert assignments across layers and balances usage over the whole pool.
- NormRouter: a routing mechanism based on L2 normalization, ReLU scoring, and a learnable scale, intended to make routing into the shared pool more stable than standard softmax routing.
The main empirical result is that reduced-pool UniPool variants use only 41.6%-66.7% of the vanilla expert-parameter budget while matching or outperforming layer-wise MoE at the tested scales.
Not Without Limitations
The first limitation is that the parameter saving is mostly about expert parameters. It is not immediately clear how large the saving is relative to the total model size, especially once attention, embeddings, dense layers, and other components are included.
The second limitation is architectural. A shared expert pool requires compatible expert input and output dimensions across the layers that use it. That makes the architecture more constrained than fully independent per-layer experts.
The third question is whether the experts are truly shared semantically across layers. It is possible that the shared pool behaves like a compact global allocation, but different layers still learn to use mostly different subsets of experts.