TL;DR TimesFM is a 200M-parameter decoder-only transformer trained on ~100B timepoints. It treats time-series patches the way LLMs treat tokens. In zero-shot, it matches or beats supervised SOTA on standard benchmarks while costing a fraction of LLM-based approaches like LLMTime.
Motivation
Classical methods (ARIMA, ETS) fit per-series and cannot transfer across datasets. LLMTime repurposes GPT-3/LLaMA-2 as zero-shot forecasters but is expensive and underperforms supervised models.
NLP and CV have foundation models, but time series is harder: no discrete vocabulary, variable context/horizon/granularity, and far less public data. Can a dedicated time series foundation model match supervised SOTA zero-shot at a fraction of the cost of repurposing LLMs?
Method
Given a context window of \(L\) timepoints \(y_{1:L}\), learn a model \(f\) that predicts the next \(H\) steps:
$$ f(y_{1:L}) \rightarrow \hat{y}_{L+1:L+H} $$optimized with MAE.
Architecture
The architecture is a decoder-only transformer that operates on patches instead of individual timepoints:
- The input is split into non-overlapping patches of length p=32 (the time series analogue of a token)
- Each processed by a residual block + positional encoding
- Then fed through 20 causal self-attention layers (16 heads, dim=1280)
- An output residual block maps each token to a prediction of length h=128
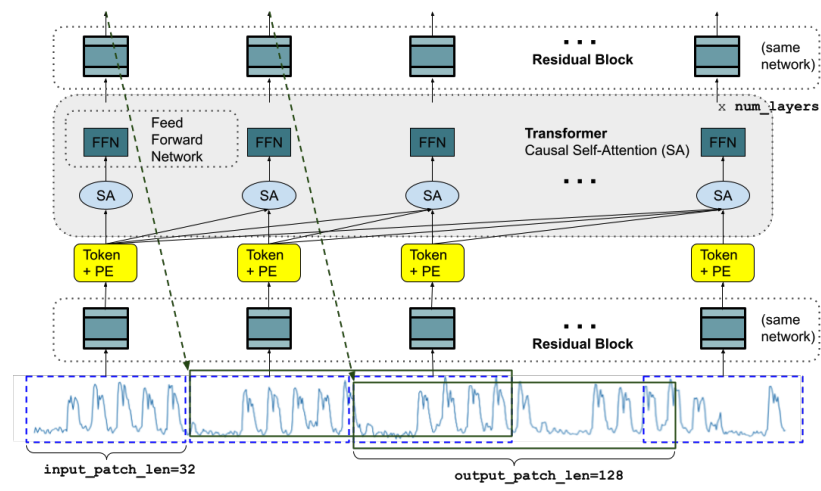
Key design choices:
- Output patches are longer than input patches (h=128 vs. p=32), so forecasting 512 steps takes 4 auto-regressive steps instead of 16. Fewer steps means less error accumulation.
- Patch masking during training: a random number of timepoints (0 to p-1) are masked from the start of the first patch, so the model learns to handle any context length.
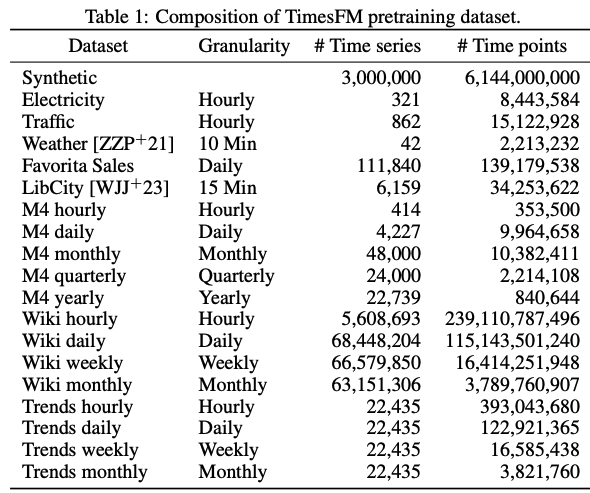
Training data
Google Trends, Wikipedia pageviews, other real-world sources, and synthetic data (ARMA, sinusoids, piecewise linear, step functions). ~100B timepoints total, mixed 80% real and 20% synthetic. The synthetic data fills granularity gaps, especially for sub-hourly frequencies underrepresented in real datasets. Loss: MSE. Trained for 1.5M iterations on 16 TPUv5e cores (~2 days for the 200M model).
Limitations
- Point predictions only. The model outputs a single value per timestep, not a distribution. A probabilistic loss (e.g. quantile regression) would let you estimate confidence intervals.
- No covariate support. The model takes only the raw time series as input. It cannot condition on external variables (e.g. temperature when forecasting electricity demand).
- Interpretability. Like any deep model, TimesFM is a black box compared to statistical methods like ARIMA or ETS where you can inspect the learned coefficients directly.