TL;DR Current beliefs suggest that a single vision model cannot achieve SOTA performance across language-centric and spatial tasks. Perception Encoder (PE) is a vision encoder demonstrates that contrastive vision-language pretraining provides versatile features suitable for both multimodal language modeling and dense spatial prediction. These diverse capabilities reside within intermediate layers rather than the model output. The authors fine-tune two PE variants to migrate these hidden representations to the final layer: one optimized for language tasks and another for spatial tasks.
Motivation
Today’s common wisdom in the vision community cites that distinct pretraining objectives are required for different task:
- Contrastive loss for zero-shot classification
- Captioning for multimodal language models (MLLMs)
- Self-supervised learning for spatial localization. Combining these strategies often leads to exponential complexity that hinders scaling.
💡 The authors identify that a robustly trained contrastive model internally contains features that match or exceed specialized models in tasks like OCR, depth estimation, and tracking.
However, these “best” embeddings are typically hidden in middle layers, while the final layer specialized for the contrastive objective performs poorly on dense spatial or fine-grained language tasks
Suggested Training Method
The authors develop a multi-stage pipeline to create a unified SOTA encoder:
- Stage #1: PE Core (Image): Training a large-scale image encoder using a refined contrastive recipe on 5.4B image-text pairs.
- Stage #2: Video Data Engine: Utilizing the image encoder to build a video captioning system (Perception Language Model) to generate dense descriptions for 22M videos.
- Stage #3: Joint Finetuning: Finetuning the image encoder on both image and video data (via average pooling across sampled frames).
- Stage #4: Alignment Tuning: Specific training to “lift” the hidden intermediate features to the final layer for either language or spatial tasks.

Stage #1: PE Core
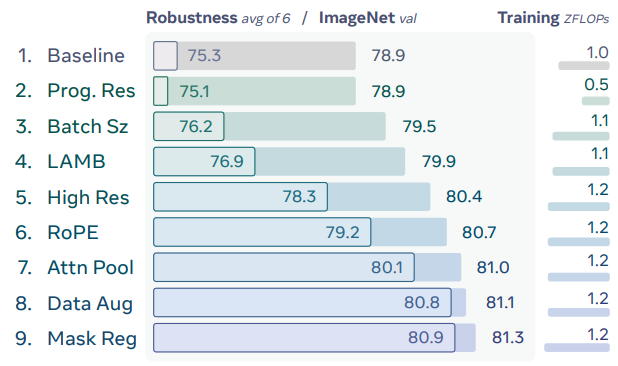
The authors improve the standard CLIP recipe through several regularization and efficiency techniques. Some of them are:
- Progressive Resolution: Training is split into stages of 98, 154, 224, and 336 resolutions to maintain performance while halving FLOPs.
- Scaled Batching: Doubling the batch size from 32K to 64K increases task difficulty by having larger chance of having hard negatives in the batch.
- 2D [[RoPE]]: Adding 2D Rotary Positional Embeddings improves extrapolation and robustness.
- Mask Regularization: A variation of MaskFeat is used where 1/16th of the batch is masked; masked tokens must match their unmasked counterparts via cosine similarity.
Stage #2: Video Data Engine
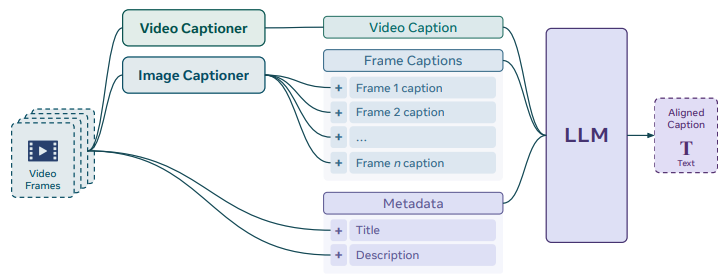
To overcome the scarcity of high-quality video-text data, the authors develop a robust data engine.
- Caption Generation: The PLM (Perception Language Model) generates initial captions.
- Llama Summarization: Video captions, frame-level captions (from Llama 3.2), and existing metadata are summarized by Llama 3.3 70B to create information-dense descriptions.
- PE Video Dataset (PVD): A released dataset of 1M diverse videos with 120K human-refined annotations, where humans removed hallucinations and added specific details like “glass bowl” or “scraping”.
Stage #3: Fine Tuning
The authors perform contrastive finetuning using the bootstrapped 22M synthetic video-text dataset.
- Temporal Strategy: The model uniformly samples $N = 8$ frames from video clips.
- Architecture: Frame-level embeddings are extracted via the image encoder and average-pooled to create a single video embedding for contrastive learning
Stage #4: Alignment
To make the internal “best” features accessible at the model output, the authors introduce two alignment methods.
A. Language Alignment
The authors adapt $PE_{core}$ to a pretrained Llama3 decoder.
- Warmup*: A 1M sample stage where only the projector is trained.
- Full Finetune: All parameters are updated on 70M diverse samples (natural images, documents, and videos) using next-token prediction.
The extracted encoder, $PE_{lang}$, excels at OCR and Document Q&A.
B. Spatial Alignment
This method resolves the “dichotomy” between semantic strength and spatial locality.
- Self-Distillation*: The model is trained as a student of its own frozen intermediate layer (Layer 41) to retain semantic features
- SAM 2 Distillation: To encourage locality, the model distills mask logits from SAM 2.1-L, which provides precise object boundaries
$PE_{spatial}$ matches state-of-the-art COCO detection performance with a much simpler decoder
Limitations
- While the core model learns versatile features during pretraining, there is no single “global” model that can perform both spatial and linguistic tasks at the final output layer. The diverse capabilities are buried in different intermediate layers, necessitating separate alignment processes to migrate specific features to the end of the network for specialized use cases
- Aligning the model for precise spatial tasks using SAM 2 distillation significantly reduces the semantic richness of the last layer’s features. Because mask logits lack high-level conceptual information, the authors must carefully balance self-distillation with spatial distillation to prevent a total loss of object-level semantics