TL;DR
Object detection has shifted from heavy, hand-engineered pipelines based on anchors and heuristics to end to end transformer architectures that learn object localization and classification jointly. This progression (from DETR 2020 to RF-DETR 2025) has reduced post-processing, improved training stability, and brought real-time inference within reach.
DETR: End-to-End Object Detection with Transformers (2020)
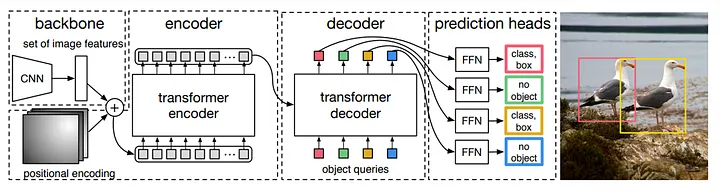
DEtection TRansformer (DETR) introduced a simple yet novel idea: formulate object detection as a direct set prediction problem solved with transformers. Instead of relying on multi-stage heuristics such as Anchor Boxes (redefined bounding boxes of specific sizes and aspect ratios spread uniformly over an image) or non-maximum suppression (a heuristic step that removes duplicated detections by suppressing overlapping boxes with lower confidence), DETR learns to predict all objects and their bounding boxes in a single forward pass.

DETR Architecture:
- The input image passes through a model backbone, extracting a set of dense feature vectors.
- These features are fed into a transformer encoder, which applies multi-head self-attention.
- Positional encodings are added to maintain spatial information since transformers are permutation invariant.
- The transformer decoder receives a fixed number of learnable object queries. Each query predicts an object or no object, and the decoder’s cross-attention layers relate queries to encoded image features. Notice this means the number of object queries is pre-defined and needs to be larger than the largest #object in the dataset.
- All objects are predicted simultaneously in a single forward pass, removing the need for post-processing like NMS.
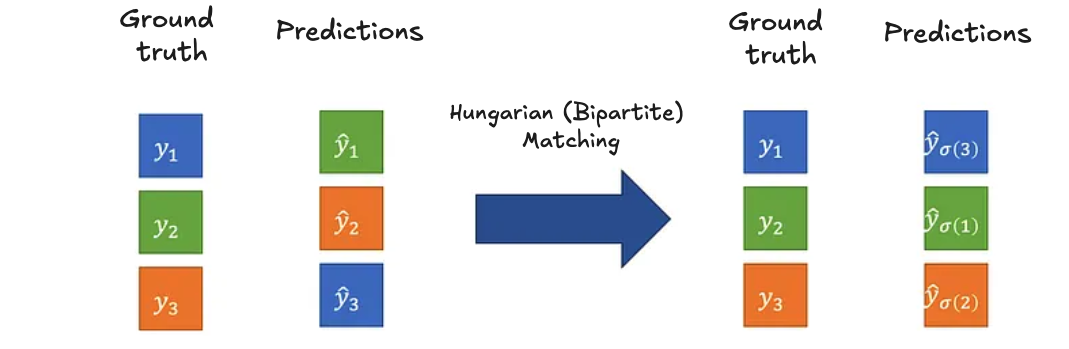
The DETR loss function is a two-step process:
- Hungarian (bipartite) matching: Finding the best unique assignment between predicted objects and ground truth by minimizing a cost combining classification confidence and bounding box similarity.
- After matching, a standard loss is computed on the matched pairs: (i) Classification loss (cross-entropy between predicted and true class labels) and (ii) Bounding box loss (a combination of L1 and IoU loss).
DETR was a breakthrough by removing the need for manual steps with anchor boxes and NMS, however, it trains slower than traditional methods and matches their accuracy without clearly beating them.
DINO: DETR with Improved DeNoising Anchor Boxes (2022)
Notice Not related to Meta’s DINOv2 or DINOv3.
DETR with Improved DeNoising Anchor Boxes (DINO) built directly upon DETR, aiming to fix its main issues: slow convergence and poor small object detection detections. It introduced a few architectural and training refinements that helped DETR-like models become faster, more accurate, and easier to train.
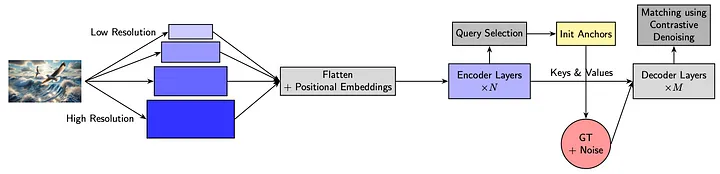
DINO’s Innovations:
Contrastive Denoising Training: DINO generates both positive (slightly perturbed) and hard negative (noisier) box queries from ground truth, explicitly teaching the model to reconstruct objects from positives and reject negatives. This minimizes duplicate predictions and improves query-to-object assignment stability.
Mixed Query Selection: DINO refines query initialization by splitting spatial and semantic components. Instead of deriving all queries from learned embeddings as in DETR, it uses encoder-predicted box coordinates to initialize query positions, while keeping the content embeddings fixed and learned separately.
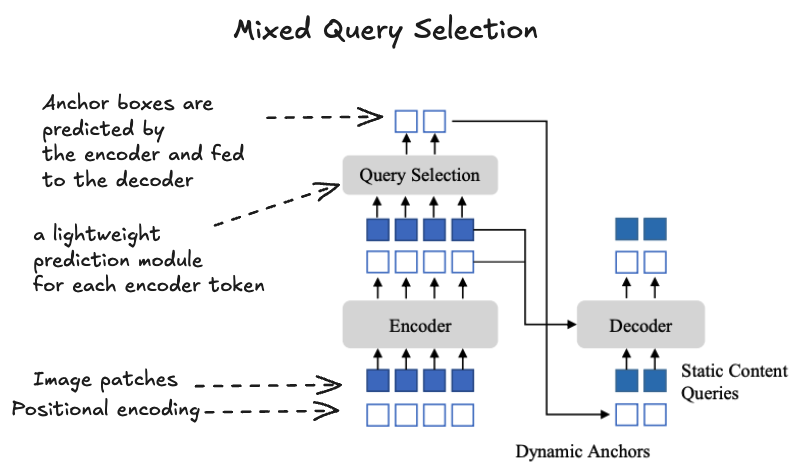
Look-Forward-Twice Mechanism: Intermediate decoder layer outputs are supervised both directly and via gradient flow from later layers
DINO set a new standard in transformer-based object detection by elegantly solving DETR’s bottlenecks. Its core ideas—learned anchors, contrastive matching, and improved gradient flow—now are used in any modern object detectors..
RF-DETR: A SOTA Real-Time Object Detection Model (2025)
Roboflow Detection Transformer (RF-DETR) is a transformer-based object detector focused on real-time performance, achieving state of the art performance (over 60 mAP on the COCO dataset) while running at 25 FPS on NVIDIA T4 GPUs.
Main novelties:
- Deformable Attention: Each feature only attends to a sparse, learned set of spatial keypoints instead of all pixels, reducing quadratic complexity.
- Multi-scale Sampling: Aggregates information from multiple feature map levels to better capture small objects.
- Latency-Aware Transformer: Reduces decoder depth and attention redundancy guided by inference profiling, maintaining performance with lower computational cost.
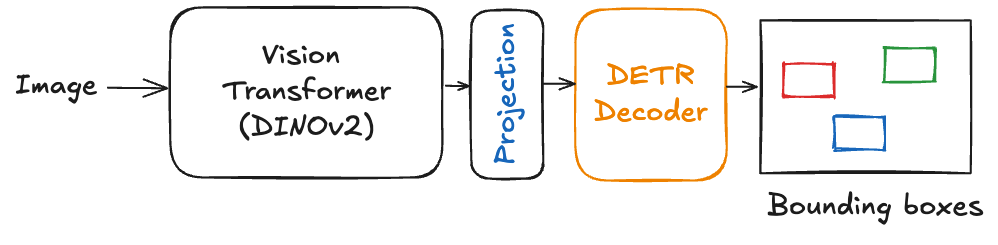
- Modern Pretraining: Adopts a DINOv2 backbone pretrained through large-scale self-supervision, enhancing transfer and low-data adaptation.
RF-DETR represents the cutting edge of real-time object detection by uniting deformable attention, efficient transformer design, and powerful pre-training. It delivers state-of-the-art accuracy with the speed needed for practical deployment.
Reference
Traditional Object Detection:
DETR (DEtection TRansformer) 2020:
DINO DETR (DETR with Improved DeNoising Anchor Boxes) 2022:
- DINO: DETR with Improved DeNoising Anchor Boxes (arXiv)
- How to DINO-DET with Improved Denoising Anchor Boxes (Medium article)
RF-DETR (Roboflow Detection Transformer) 2025: