TL;DR
Grounding DINO is an open-set object detector that integrates natural language supervision into the DETR-style DINO framework: Instead of being limited to a fixed set of classes, it allows specifying text prompts (e.g., zebra, traffic light) and find those objects within images at inference time.
The model achieves this by coupling image and text representations throughout its architecture using cross-modality attention and language-conditioned query mechanisms.

Motivation
Closed‑set detectors are limited to a fixed label list and cannot recognize unseen categories without new annotations and retraining. Even when language is added, many systems align vision and text only once, leaving region features weakly language aware and brittle for fine‑grained phrases like “left lion with head up,” while CLIP‑style global pretraining lacks the region–phrase alignment needed for precise detection.
Why prior methods fall short:
- CNN and two‑stage designs complicate deep, repeated language fusion. As a result, prior work often fuses only in the neck or only at the head, missing alignment at query initialization and decoding, which degrades zero‑shot detection.
- Prompt encoding choices also hurt: sentence‑level features are too coarse, and naively concatenated word lists cause spurious attention among unrelated categories, diluting token semantics, weakening text‑guided query selection, and harming contrastive region
Method
Grounding DINO proposes language-aware detection. The key hypothesis is that image regions and language phrases can share a unified semantic space, allowing detection of unseen concepts described in free-form text. By grounding textual queries in images, the detector can generalize to open-set scenarios without costly relabeling.
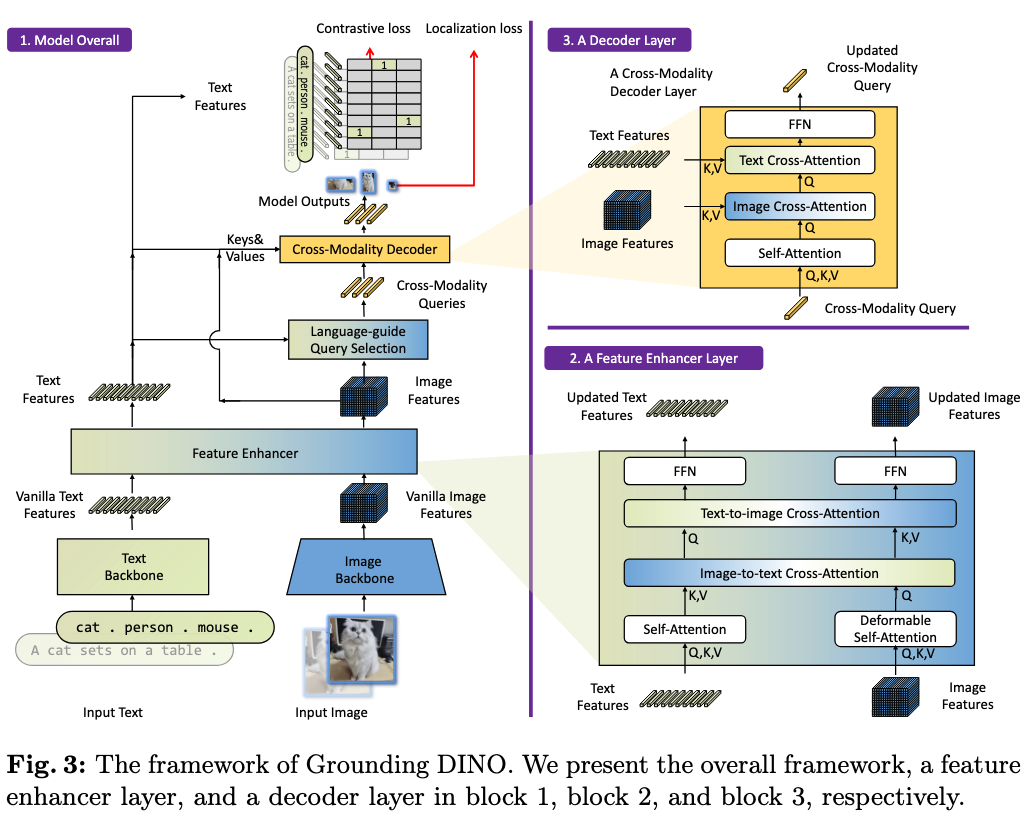
Grounding DINO builds on “DETR with Improved DeNoising anchor boxes” (and not Meta’s DINO), enhancing it from a single-modality object detector to a vision-language model via cross-modality fusion. The system follows a dual-encoder, single-decoder architecture:
- Image backbone: Uses a hierarchical transformer backbone (Swin-L) to extract multi-scale features from the input image. Multi-resolution outputs allow detection of both small and large objects.
- Text backbone: A BERT-like encoder encodes input text queries.
- Feature enhancer: Combines image and text features through a sequence of attention operations (self-attention, text-to-image cross-attention, and image-to-text cross-attention) to produce fused multimodal tokens.
- Language-guided query selection:
- Compute similarity between every image token and every text token. Treat high-similarity image tokens as better seeds for queries
- Pick the top image positions (e.g., 900) with the strongest text-aligned evidence, then form decoder queries from those positions
- Cross-modality decoder: Apply multiple cross-attention layers linking textual and visual features, producing final bounding boxes and alignment scores.
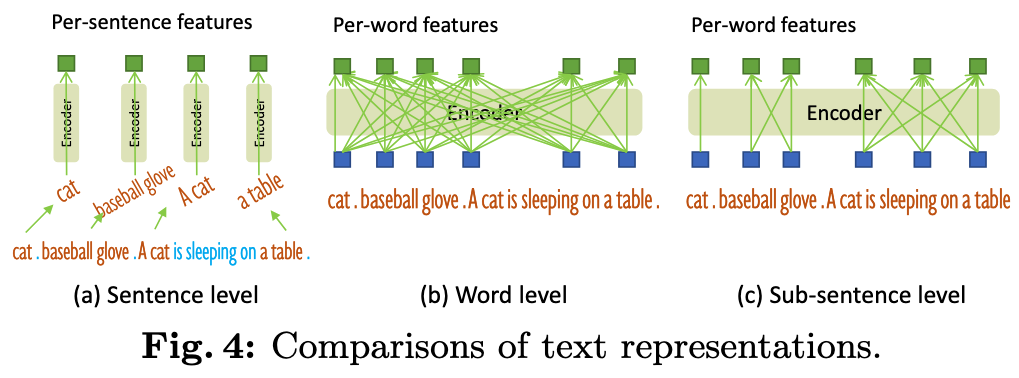
Common prompt encoding choices for conditioning detection on text include:
- Sentence‑level encodes an entire prompt into a single vector. This maintains interference across words but loses fine‑grained token detail needed for precise region–token alignment.
- Word‑level keeps per‑token features and allows batching many category names in one forward pass, yet concatenating categories induces spurious attention between unrelated words To fix this, Grounding DINO introduces sub‑sentence masking: per‑token features are retained, but attention is blocked across unrelated category spans so “cat” does not attend to “baseball glove” when both appear in a concatenated list.
The model is pre-trained jointly on a mixture of datasets:
- Detection data: COCO, Objects365, OpenImages.
- Grounding/Referring expressions: Flickr30K Entities, Visual Genome.
- Caption data: LAION, Conceptual Captions.
For training resources, smaller variants are trained with 16 V100 GPUs while the large variants use 64 A100 GPUs.
Limitations
- Grounding DINO operates in a text-conditioned fashion: it requires the query phrase before inference. Detecting many distinct objects demands multiple passes, increasing computational cost.
- Inference latency remains higher than closed-set detectors due to the heavy transformer backbone and cross-attention computations.
Resource
[Grounding DINO][https://arxiv.org/abs/2303.05499]