TLDR
The DINO series advances self-supervised learning for vision transformers through iterative architectural and data refinements. DINOv1 introduces student-teacher distillation on ImageNet-1k. DINOv2 scales to 142M curated images with patch-level objectives. DINOv3 reaches 1.7B Instagram images with register tokens, new Gram matrix based loss, with a custom 7B-parameter ViT, achieving state-of-the-art performance on dense prediction tasks (like instance segmentation) while maintaining a frozen backbone.
Motivation
Supervised pretraining on ImageNet has dominated vision models, but manually annotating large datasets is expensive and constrains representation quality to label granularity. Self-supervised learning (SSL) offers an alternative by leveraging unlabeled data at scale. Early SSL methods like contrastive learning require careful negative sampling and large batch sizes. DINO sidesteps these constraints through knowledge distillation between student and teacher model operating on augmented views of images.
DINOv1
DINOv1 employs a Vision Transformer for both student and teacher networks. The student receives multiple augmented crops (2 global at 224×224, several local at 96×96) while the teacher processes only global views.
The training objective minimizes cross-entropy between student and teacher distributions:
$$ \min_{\theta_s} H(P_t, P_s) = - \sum_{i=1}^K P_t^{(i)} \log P_s^{(i)} $$where \(P_t\) and \(P_s\) are teacher and student outputs respectively.
The core challenge is preventing trivial solutions where all images collapse to identical representations. Three mechanisms prevent this collapse:
- Exponential moving average updates** for teacher weights: \(\theta_t \leftarrow \lambda \theta_t + (1-\lambda)\theta_s\) with \(\lambda = 0.996\)
- Centering teacher outputs by subtracting running mean
- Sharpening via low temperature softmax \(\tau_t = 0.04\) for teacher vs higher temperature \(\tau_s = 0.1\) for student
The architecture uses standard ViT variants (ViT-S/16, ViT-B/16) trained on ImageNet-1k for 300 epochs with no explicit contrastive loss nor negative pair.
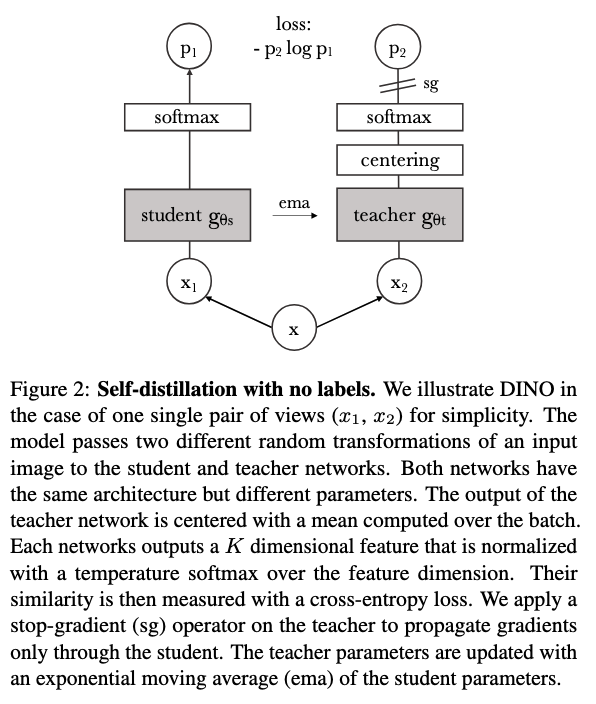
DINOv2
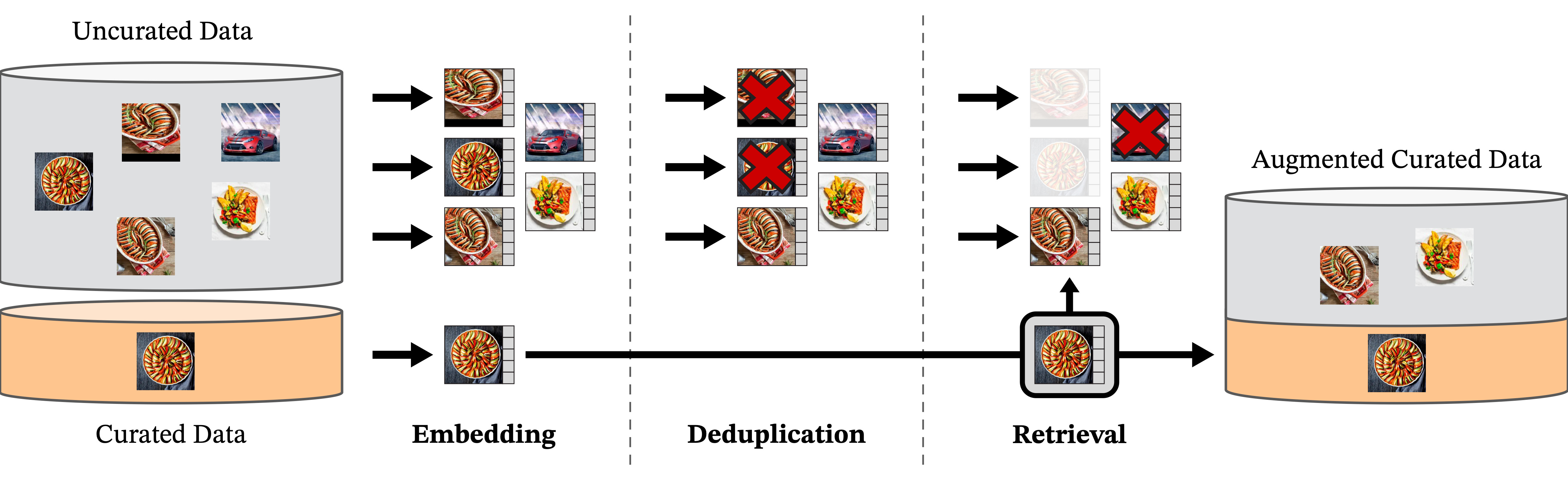
Dataset expansion. DINOv2 addresses DINOv1’s data hunger by constructing LVD-142M, a 142-million image dataset curated through a multi-stage pipeline:
- Start with ~1.2B uncurated web images
- Use embeddings from curated sources (ImageNet-22k, ImageNet-1k train split, Google Landmarks, fine-grained datasets) as retrieval seeds
- Deduplicate using copy detection to remove near-duplicates
- Retrieve additional images whose DINO embeddings lie close to curated exemplars
- Cluster retrieved images and subsample to maintain diversity
This process balances coverage of visual concepts while filtering low-quality data.
Architectural modifications.
- Separate projection heads for global \([CLS]\) token and patch tokens, preventing interference between objectives
- Patch-level loss from iBOT: randomly mask 40-50% of student patches, predict teacher features for masked positions using unmasked context
- Koleo regularizer to prevent dimensional collapse in feature space
- SwiGLU activation replacing standard GELU
Training enhancements.
- Replace centering + sharpening with Sinkhorn-Knopp batch normalization for numerical stability
- Mixed-resolution training with crops at \(\{224, 448\}\) for global views
- Longer training schedules (up to 500k iterations)
The combined global and local objectives yield representations that excel at both image-level retrieval and dense prediction tasks like segmentation.
DINOv3
Analysis revealed that DINOv2 transformers “smuggle” global information into irrelevant background patches through attention, contaminating patch representations. Register tokens fix this by providing dedicated slots for storing global context separate from spatial features.
Dataset expansion. DINOv3 uses 1.7B images from public Instagram posts. The curation pipeline adds balanced clustering:
- Embed all images with DINOv2-L
- Cluster embeddings into 10k groups
- Subsample images uniformly across clusters to ensure representation of rare visual concepts
- Retrieve images near trusted seed datasets (ImageNet, fine-grained benchmarks) to prioritize task-relevant concepts
This combines diversity (via clustering) with task alignment (via retrieval).
Architecture scaling.
- Custom ViT-7B, the largest vision-only transformer to date
- Patch size increased from 14 to 16 pixels for computational efficiency
- Improved RoPE positional embeddings with box jittering augmentation for handling variable resolutions and aspect ratios at inference
Training innovations.
- Gram matrix regularization to preserve intra-patch consistency. The loss operates on \(G = FF^T\) where \(F\) is the matrix of patch features, pushing student Gram matrices toward early-teacher values
- Mixed-resolution training with global crops sampled from \(\{512, 768\}\) and local crops from \(\{112, 168, 224, 336\}\)
- Post-training alignment with text encoders while keeping vision backbone frozen, enabling CLIP-style zero-shot capabilities without degrading visual representations
Applications
Most of the results where obtained using a frozen backbone: Most detection models fine-tune encoders, but DINOv3 demonstrates competitive performance with a completely frozen ViT, simplifying deployment and preserving general-purpose features.
Unsupervised object discovery uses TokenCut, a non-parametric graph algorithm that segments objects by clustering patch features based on similarity
Video instance segmentation propagates masks across frames via nearest-neighbor label transfer in feature space. Given ground-truth masks for frame 1, the algorithm finds patches in frame 2 whose DINOv3 features lie closest to labeled patches in frame 1, transferring labels accordingly
Video classification trains a shallow 4-layer transformer probe on frozen patch features extracted per frame, enabling spatio-temporal reasoning without backpropagating through the backbone
Object detection uses a modified Plain-DETR architecture where the ViT backbone remains frozen during training and inference. Only the detection head and transformer decoder receive gradient updates
Limitations
- Instagram bias in DINOv3’s dataset may favor certain visual styles and demographics over others, potentially affecting performance on specialized domains
- Text alignment** in DINOv3 keeps vision frozen, which simplifies training but may limit multimodal reasoning compared to joint training
- Frozen backbone assumption works for many tasks but may underperform full fine-tuning when training data is abundant and task-specific
