TL;DR
Retrieval-Augmented Generation (RAG) grounds large-language-model (LLM) answers in external documents, yet hallucinations persist. Existing detectors either rely on expensive LLM as a judges or on encoder classifiers that truncate context and lose evidence. LettuceDetect introduces a long-context, token-level classifier built on ModernBERT. It surpasses prior encoder baselines while remaining markedly more efficient than LLM-based judges.
Background
LLMs hallucinate when generated claims are not supported by retrieved context. Encoder detectors shorten inputs to fit model limits (context size), reducing recall, whereas generative judges process full context but incur high latency and cost.
Method
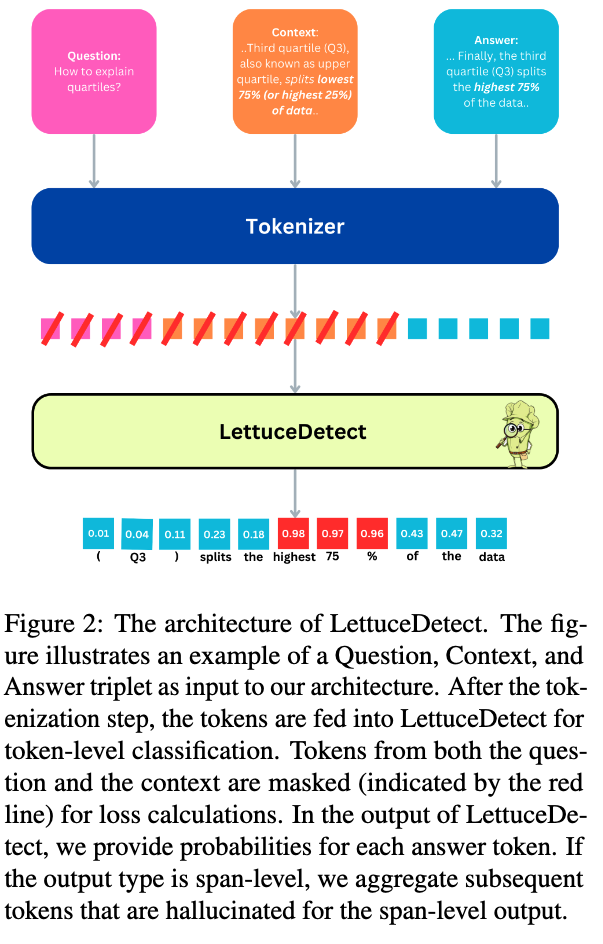
LettuceDetect combines a long-context encoder with fine-grained supervision to achieve both coverage and efficiency. The LettuceDetect model is as follows.
- Input: Concatenate retrieved context, question, and answer, separated by [CLS] and [SEP] tokens
- ModernBERT architecture as the backbone: Useful for long sequences to encode the entire concatenated input
- Each Answer tokens are predicted as supported (0) or hallucinated (1): The model outputs per-token hallucination probabilities
- Consecutive tokens whose probability exceeds 0.5 are aggregated into hallucination spans
Limitations
- Like similar RAG systems, performance depends on retrieval quality: irrelevant context can yield false alarms
- Generalization beyond the RAGTruth dataset is untested
- Tokens are labeled hallucinated when their probability exceeds a fixed 0.5 threshold. Replacing this with a sequence-level decoder (Viterbi algorithm) could deliver more coherent, answer-level classifications