TL;DR
Traditional 3D reconstruction relied on iterative visual-geometry optimization (e.g., Bundle Adjustment). Recent work explored integrating machine learning via differentiable Bundle Adjustment, but remained slow and limited. VGGT (Visual Geometry Grounded Transformer) is a large feed-forward transformer that predicts all key 3D scene attributes—camera parameters, depth maps, point maps, and 3D point tracks—directly from one or many images in a single forward pass. It removes the need for geometry processing, achieves state-of-the-art results in multiple benchmarks, and runs in under a second.

Background
3D reconstruction has traditionally been approached using visual-geometry methods with iterative optimization techniques like Bundle Adjustment (BA). While machine learning has played a complementary role in tasks like feature matching and depth prediction, geometry post-processing remained a crucial component, increasing complexity and computational cost. Recent approaches showed promise in direct neural reconstruction but were limited to processing only two images at once and still required post-processing for multi-view reconstruction.
Method
VGGT Achieving state-of-the-art results in multiple 3D tasks: Camera parameter estimation, Multi-view depth estimation, Dense point cloud reconstruction, 3D point tracking. Its main novelty is end-to-end training, removing the need for geometry optimization in post-processing.
Architecture
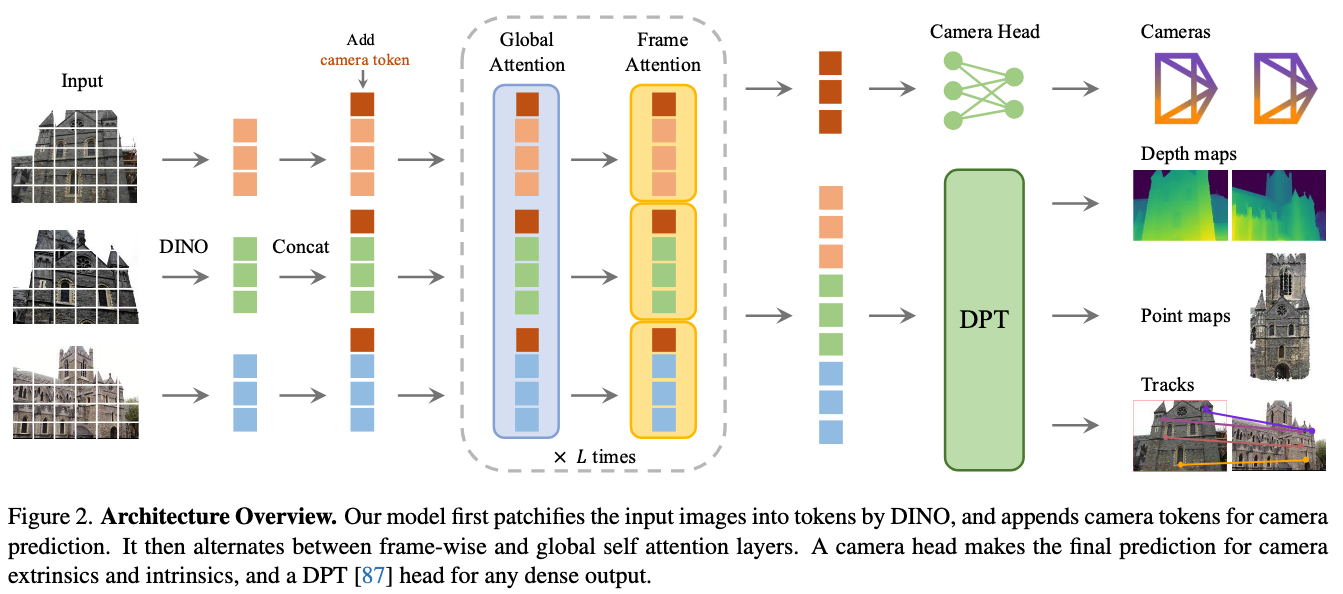
Input Processing.
- Takes one to hundreds of input images
- Images are broken down into patches that converted into tokens using DINO
- Appends camera tokens for camera prediction
Transformer Design.
- Including frame-wise and global self-attention layers
- Alternates between frame-wise and global self-attention layers
- Uses a standard transformer architecture with minimal 3D-specific inductive biases
- Processes all images simultaneously in a single forward pass
Output Heads.
- Camera head for predicting extrinsics and intrinsics
- DPT-based head for dense outputs (depth maps, point maps). DPT assembles multi-stage transformer tokens into image-like features at different resolutions, then uses a convolutional decoder to progressively build full-resolution predictions, benefiting from a high-resolution, globally-aware transformer backbone.
- Unified prediction of all 3D attributes in one pass
Training
The model is trained end-to-end on a large and diverse set of real and synthetic datasets with 3D annotations. The loss function combines supervision on multiple 3D tasks:
$$ L = L_{camera} + L_{depth} + L_{pmap} + \lambda L_{track} $$- Camera loss: Huber loss on camera intrinsics and extrinsics.
- Depth loss: Aleatoric-uncertainty loss weighted by predicted confidence maps, includes pixel-wise and gradient-based terms.
- Point map loss: Same as depth loss, but applied to predicted 3D point maps.
- Tracking loss: Uses CoTracker-style correlation with self-attention to predict 2D correspondences across views; includes visibility estimation.
Limitations
- Seems difficult to train: From the paper: “We use a cosine learning rate scheduler with a peak learning rate of 0.0002 and a warmup of 8K iterations”. This is not a standard setup which indicates many iteration of training to make it work
- The removal of geometry supervision weakens “grounding” of the model with a greater chance of hallucination.
- Limited support for fisheye/panoramic imagery and failure cases under extreme rotations or strong non-rigid deformations.