TL;DR
Transformer models often map multiple concepts to the same neuron, making it unclear what features they learn. This work makes inner representations interpretable by using a sparse autoencoder layer to map neurons to concepts. This method extracts relatively monosemantic concepts, can steer transformer generation, and shows that 512 neurons can represent tens of thousands of features.
Method
A major challenge in reverse engineering neural networks is the curse of dimensionality: as models grow, the latent space volume increases exponentially.
A sparse autoencoder, a weak dictionary learning algorithm, is used to generate interpretable features from a trained model. This method decomposes multi-layer perceptron (MLP) activations into more interpretable concepts. Demonstrated with a one-layer transformer with a 512-neuron MLP layer, sparse autoencoders are trained on activations from 8 billion data points. Analysis focuses on 4,096 features.
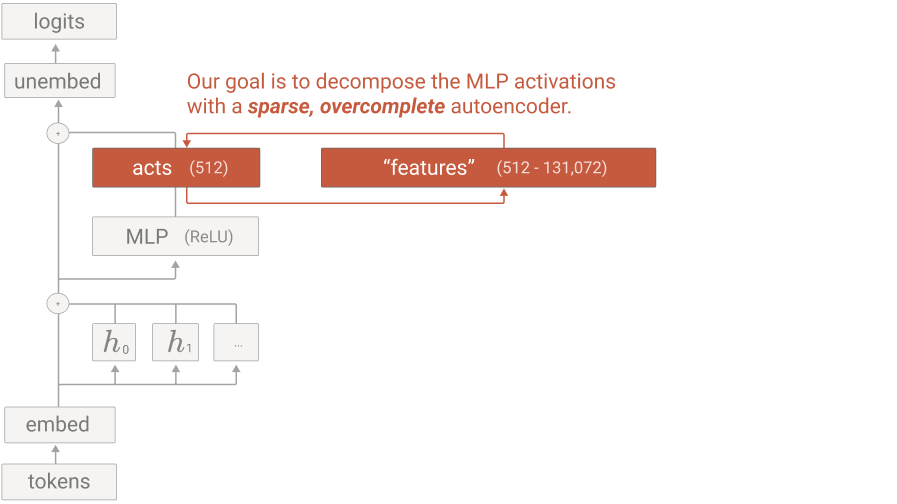
What makes a good decomposition?
A useful decomposition approximates MLP activations as a sparse weighted sum of features if:
- The conditions under which each feature is active can be interpreted.
- The downstream effects of each feature can be interpreted.
- The features explain a significant portion of the MLP layer’s functionality (measured by loss).
Sparse autoencoders show a more promising direction for interpreting inner representations than architectural changes: Attempts to induce activation sparsity during training to produce models without superposition failed to result in cleanly interpretable neurons.
Validating the approach
Several metrics guide the investigation of the validity of sparse autoencoders to represent internal concepts:
- Manual inspection: Do the features seem interpretable?
- Feature density: The number of “live” features and the percentage of tokens on which they fire.
- Reconstruction loss: The goal is to explain the function of the MLP layer, so the MSE loss should be low.
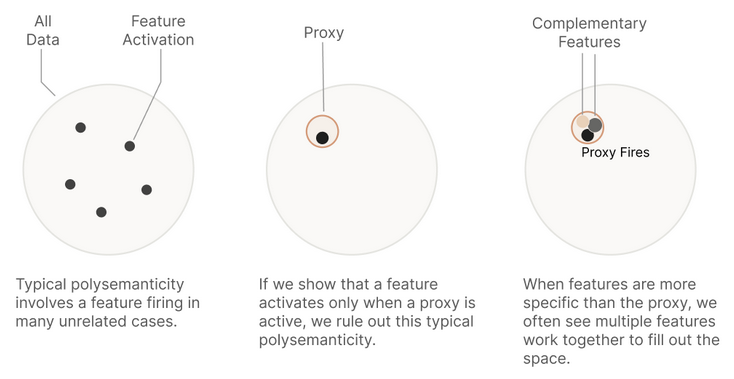
Limitations
- This study uses a one-layer transformer. It’s unclear if the results generalize to larger models like GPT.
- There’s no quantitative way to confirm if the autoencoder approach works.
- Features were picked for easier analysis. It would be interesting to see results of more vague concepts like “fantasy games”.