TL;DR
Vision Transformers (ViTs) outperform Convolutional Neural Networks (CNNs) with sufficient data but are data-hungry, limiting their use with small datasets. The authors propose a method to train ViTs with limited data by pre-training with label smoothing, lower resolution images, and parametric instance discrimination, followed by fine-tuning on the target task.
Method
Training a Vision Transformer on small datasets involves two steps
- Self-supervised pretraining:
- Parametric instance discrimination: Classify each image as its own class.
- CutMix: Mix images patches and labels proportionally to the patch size
- Label smoothing: Modify one-hot labels to update weights more frequently.
- Small resolution: Use lower resolution images during pre-training since it was shown to prevent overffiting
- Supervised fine-tuning on the target dataset.
Parametric instance discrimination: For a training set of N samples, classify each image as its own class using a fully connected layer (FC). This is feasible with limited data due to manageable GPU memory requirements.
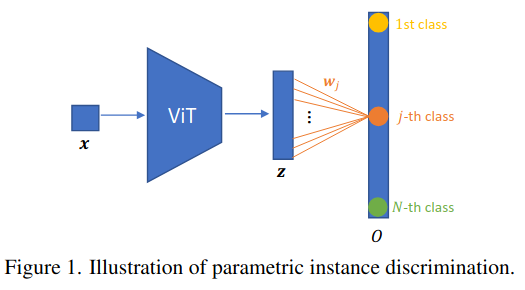
Parametric instance discrimination is approximately equivalent to contrastive loss, they both have the following terms:
- Alignment term encouraging more aligned positive features.
- Uniformity term encouraging the features to be roughly uniformly distributed on the unit hypersphere.
Its advantage is in simplicity and better training stability oven the contrastive loss training.
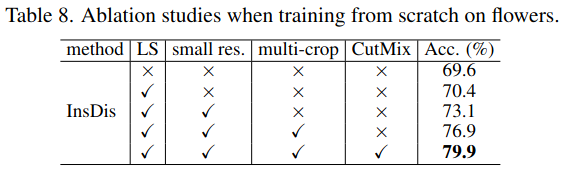
Limitations
Unclear if using this method, ViT ables to outperforms CNNs with limited data