TL;DR
Traditional item retrieval methods use user and item embeddings to predict relevance via inner product computation, which is not scalable for large systems. Generative models predict item indices directly but struggle with new items. This work proposes a hybrid model that combines item positions, text representations, and semantic IDs to predict both the next item embedding and several possible next item IDs. Then only this item subset along the new items are in the inner product with user representations.
Generative Retrieval
To train a generative model for predicting the next semantic item ID:
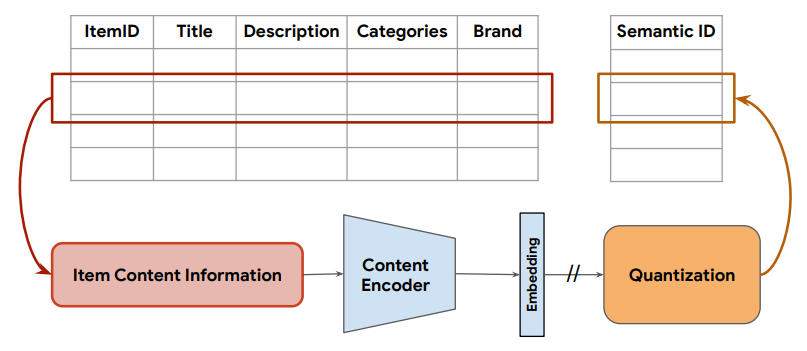
- Collect textual descriptions for each item to generate text embeddings, which are quantized into semantic IDs using an RQ-VAE.
- Replace item IDs in interaction histories with their semantic IDs.
- Train a Transformer model to predict the next semantic ID sequence based on the last \(n\) items a user interacted with.
- Use beam search during inference to retrieve candidate items based on user interactions.
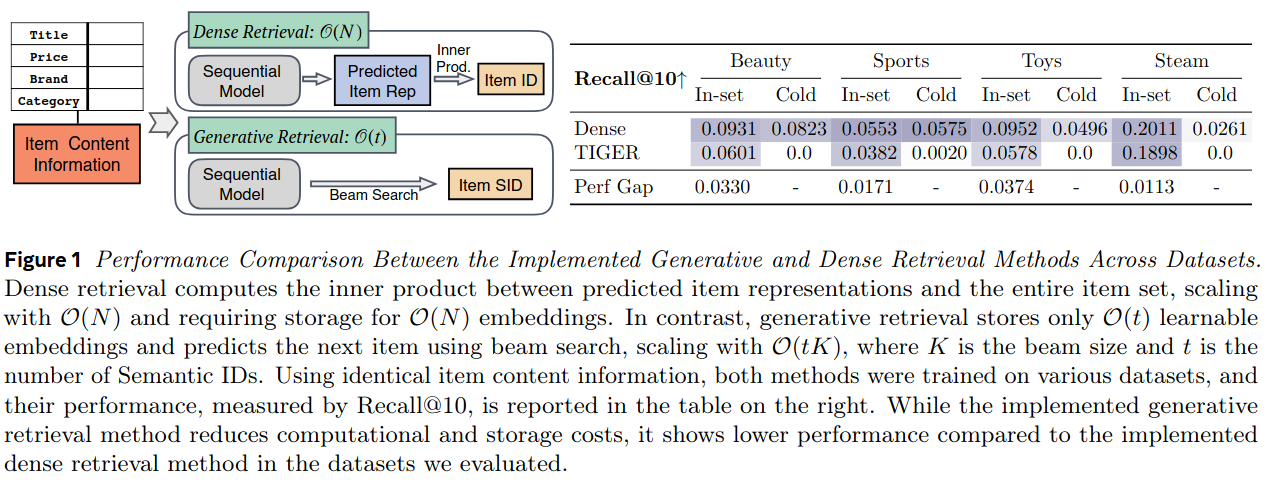
Comparison between Dense and Generative Retrieval
Dense retrieval uses maximum inner product search, while generative retrieval uses next-token prediction via beam search. Key differences include:
- Dense retrieval requires O(N) embeddings for \(N\) items, whereas generative retrieval needs O(t) tokens for user interactions.
- The effectiveness of semantic IDs in capturing item semantics is uncertain.
- Generative retrieval performs poorly with cold-start items due to overfitting to training data.
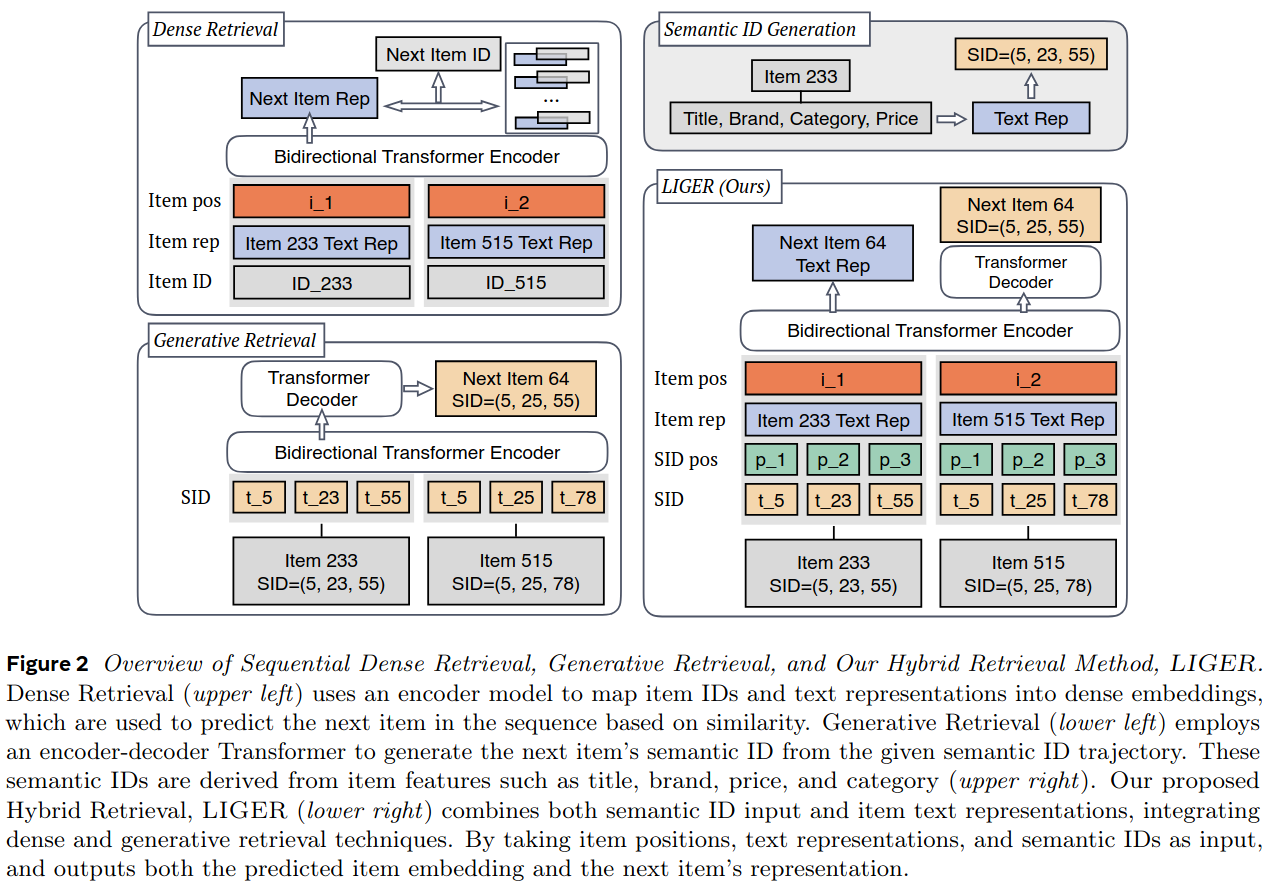
Method for Combining Dense and Generative Retrieval
The SID-based hybrid model uses dense retrieval on a limited set of candidates generated by generative retrieval, improving performance while maintaining minimal storage requirements.
The hybrid model approach is as follows.
- Construct input embeddings by combining positional encoding, semantic ID, and item text representation.
- Train a model with cosine similarity loss and next-token prediction loss on the next item’s semantic IDs. This model produces both embeddings and semantic ID.
- During inference, retrieve \(K\) items via beam search, supplement with cold-start items, and rank using the encoder’s output embeddings.
Limitations
- The assumption that cold-start items are sparse may not always hold.
- Regular training on new items is necessary for the next SID predictor.
- The hybrid model’s complexity may increase inference time, impacting real-time recommendation performance.
Resource
Representing Users and Items in Large Language Models based Recommender Systems