TL;DR
Multimodal models are advancing rapidly across research and industry. Their architecture can be characterized into four different types.
- Types A and B integrate multimodal data within the internal layers of the model.
- Type A relies on standard cross-attention for fusion
- Type B introduces custom-designed layers for multimodal fusion
- Types C and D fuse multimodal at the input stage (early fusion)
- Type C uses modality-specific encoders without tokenization
- Type D employs tokenizers for each modality at the input and able to generate outputs with multimodalities (any-to-any multimodal models)
Model Architecture Overview
Models processing images, audio, or video alongside text have evolved significantly. Recent developments have emphasized image-text integration across diverse vision-language tasks, resulting in varied multimodal architectures based on the fusion method.
Type A: Standard Cross-attention based Deep Fusion (SCDF)
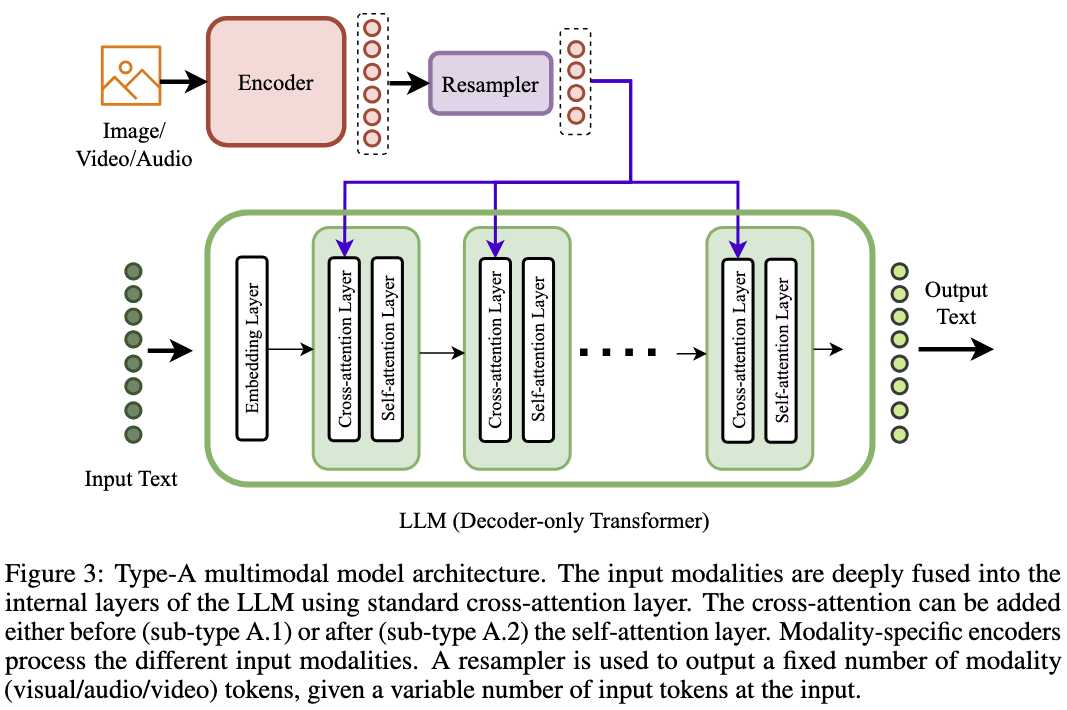
- Uses a pre-trained language model (LLM)
- Multimodal inputs (images/audio/video) pass through modality-specific encoders
- A resampler generates embeddings suitable the requirements of the decoder layer
- Cross-attention layers facilitate deep fusion of multimodal data within the model’s layers
Examples of models in this category: Flamingo, OpenFlamingo, Otter (trained on MIMIC-IT dataset on top of OpenFlamingo), MultiModal-GPT (derived from OpenFlamingo), PaLI-X, IDEFICS (open-access reproduction of Flamingo), Dolphins (based on OpenFlamingo architecture), VL-BART, and VL-T5.
Type B: Custom Layer based Deep Fusion (CLDF)
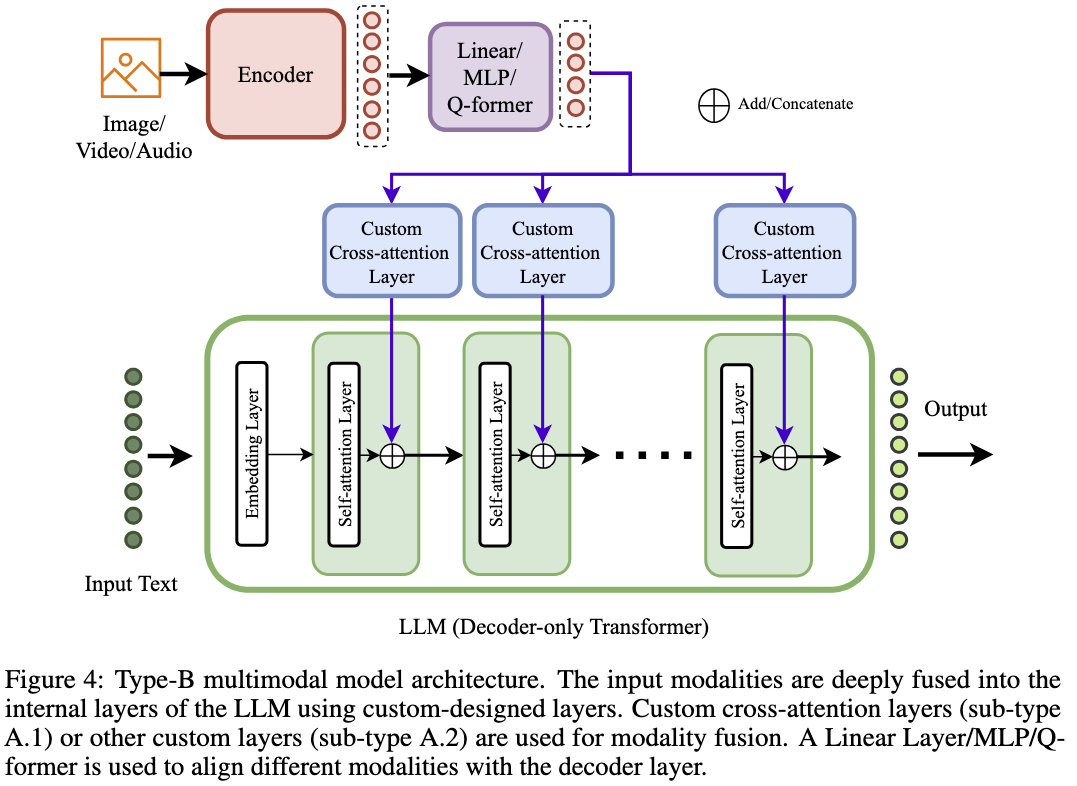
- Employs a pre-trained LLM
- Modality-specific encoders process the multimodal input
- Custom cross-attention layers, such as learnable linear layers or MLPs, integrate multimodal data in the model’s internal layers
- Some implementations include a learnable gating factor to control cross-attention contributions
Examples of models in this category: LLaMA-Adapter, LLaMA-Adapter-V2 G, CogVLM, mPLUG-Owl2, CogAgent, InternVL, MM-Interleaved, CogCoM, InternLM-XComposer2, MoE-LLaVA, and LION.
Type C: Non-Tokenized Early Fusion (NTEF)
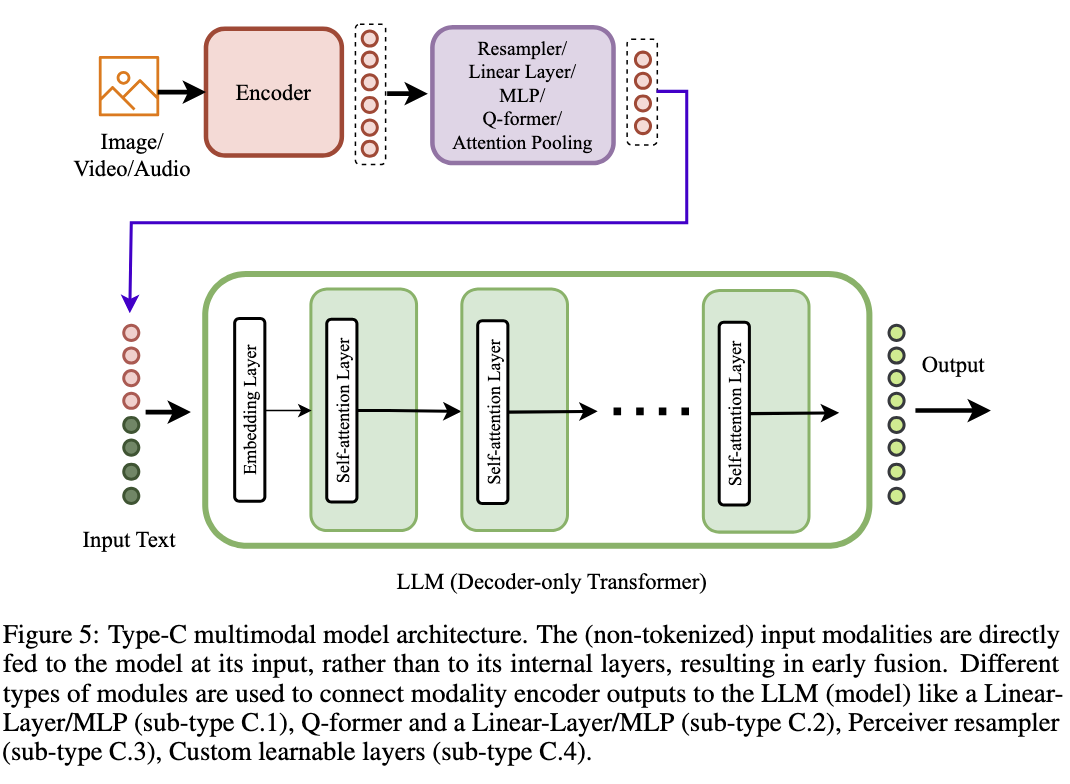
This approach stands out as the most widely adopted multimodal model architecture.
- A pretrained LLM acts as the decoder without architecture modifications.
- Modality-specific encoders are employed.
- Multimodal fusion occurs at the input stage (without tokenization, a non discrete inputs are fed to the model).
Training procedure:
- Pretraining: Freeze LLM and Encoder. Only train the projection layer/s for Vision-Language alignment.
- Instruction and alignment tuning: Train projection layer and LLM for multimodal tasks.
Examples of models in this category: LLaVA, PaLM-E, MiniGPT-v2, BLIP-2, MiniGPT-4, Video-LLaMA, defics2, MM1
Type D: Tokenized Early Fusion (TEF)
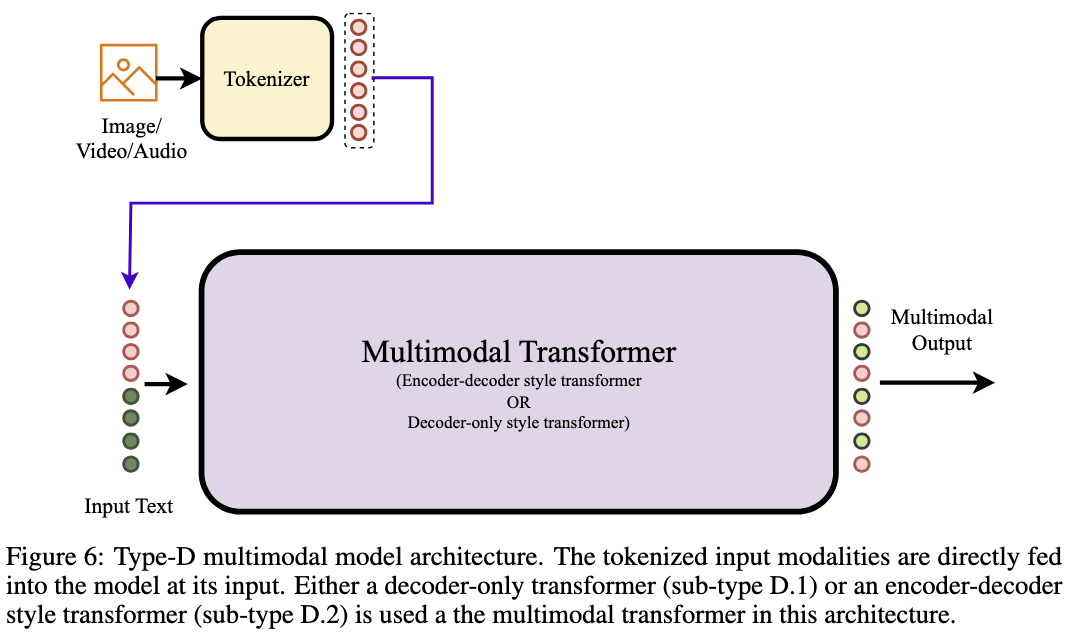
Models of this type are trained auto-regressively to generate text tokens along with other modalities tokens (image, audio, and videos).
- Uses a pretrained LLM as the decoder
- Modality-specific encoders are applied
- Tokenizes all modalities at the input (discrete tokens)
- Capable of generating outputs in multiple modalities
Examples of models in this category: LaVIT, TEAL, CM3Leon, VL-GPT, Unicode, SEED, 4M, Unified-IO, Unified-IO-2.