TL;DR
State-of-the-art language models are primarily decoder-only, focusing on token prediction rather than producing rich contextualized embeddings for downstream tasks. LLM2Vec introduces an unsupervised method to transform decoder-only models into encoders. This approach involves: (i) enabling bidirectional attention, (ii) training on masked token prediction, and (iii) incorporating unsupervised contrastive learning. The result is that these converted models outperform traditional encoder-only models.
Background
Until recently, large language models (LLMs) were predominantly based on bidirectional encoders or encoder-decoder frameworks like BERT and T5. However, the field has shifted towards decoder-only models, which use causal attention mechanisms.
Decoder-only models are more sample-efficient because, during training, the same input sequence is reused multiple times: The model is trained to predict the next token based on progressively longer portions of the sequence, allowing it to learn from the entire sequence step by step. However, the downside is they struggle to create rich contextual embeddings since causal attention limits them from capturing information across the entire input sequence.
Method
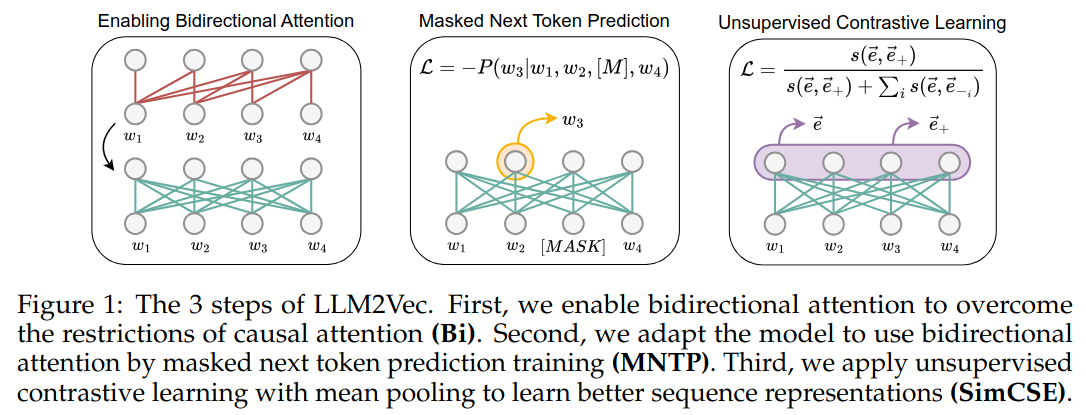
LLM2Vec’s method has three key steps:
Enabling bidirectional attention. Replace the causal attention mask in decoder-only LLMs with an all-ones matrix to allow information to flow in both directions across the sequence.
Masked token prediction. Feed an arbitrary sequence, mask a fraction of tokens, and train the model to predict the masked tokens using both past and future context.
Unsupervised contrastive learning. To enhance sequence-level representations, the model processes the input sentence twice with independently sampled dropout masks. The goal is to maximize similarity between these two representations while minimizing similarity to representations of other sentences, similar to the SimCSE method
The training procedure begins with the first two steps, followed by contrastive learning. For efficiency, the authors used Low-Rank Adaptation (LoRA) in their experiments.
Limitations
The approach requires retraining, which can be computationally expensive for large, modern models. Although LoRA improves training efficiency, resource demands might still be too big.
Resource
Published in COLM 2024 arxiv