TL;DR
In the fashion domain, visually distinct products may share fine-grained attributes like sleeve length or collar shape. Traditional methods of finding similar products often overlook these details, leading to irrelevant results for the user. To address this, the authors propose a model with two branches: a global branch that processes the entire image and a local branch takes a Region Of Interest (ROI) of specific attributes, identified through a spatial attention layer in the global branch. This approach improves the retrieval of items with similar attributes.

Method
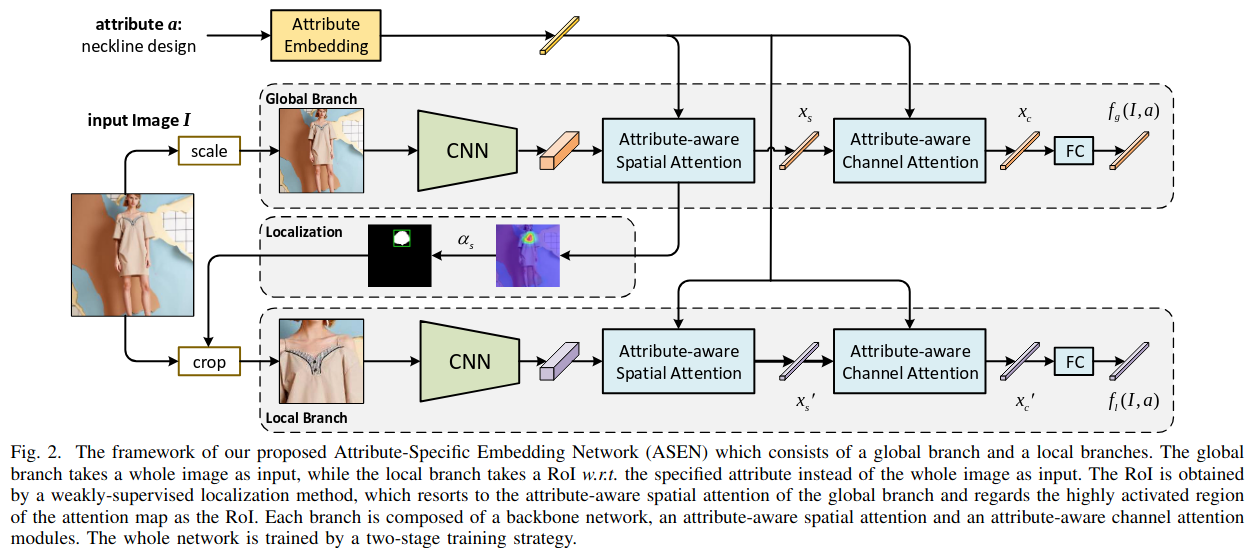
The model has two main components: a global branch and a local branch.
The global branch takes the entire image as input and generates Regions of Interests (ROIs) for predefined attributes. It uses two types of attention: attribute-aware spatial attention (ASA) and attribute-aware channel attention (ACA). The latter (ACA) is necessary sine the same region can correspond to multiple attributes, such as both collar design and collar color. With the both type of attentions, the global branch is able to identify the relevant regions of each attribute.
The local branch focuses on a zoomed-in ROI related to a specific attribute of the image. With this localized region, the local branch can extract more fine-grained features. The ROI is determined by the areas that show the highest activation in the attribute-aware spatial attention map from the global branch.
Training Procedure
The goal is to create multiple embedding spaces, each focused on a specific attribute. In these spaces, products with the same attribute value (e.g., Round Neck) are close together than products with different values (e.g., V Neck) are far apart. This is achieved using a triplet ranking loss, applied to both the global and local branches.
Training consist of two stages. First, the global branch is trained until it produces reliable ROIs. Then, both the global and local branches are trained together, with an additional alignment loss that ensures the original images and their corresponding localized regions are consistently embedded (features are similar).

Limitations
Attributes are predefined: The model relies on a fixed set of predefined attributes which means that a new attribute added to the system requires retraining the model. This limitation reduces the model’s flexibility and scalability, particularly in domains like fashion where new styles or features frequently emerge.
The method produces per-attribute embeddings: Each attribute has its own separate embedding space, meaning the model creates individual embeddings for each attribute (e.g., sleeve length, collar shape). These embeddings are not fused or integrated into a single global feature representation. In a product retrieval system, this separation requires that each attribute embedding be stored and indexed separately. As a result, the system may require a large memory footprint.
Resource
Published in IEEE TRANSACTIONS ON IMAGE PROCESSING, MARCH 2021 arxiv