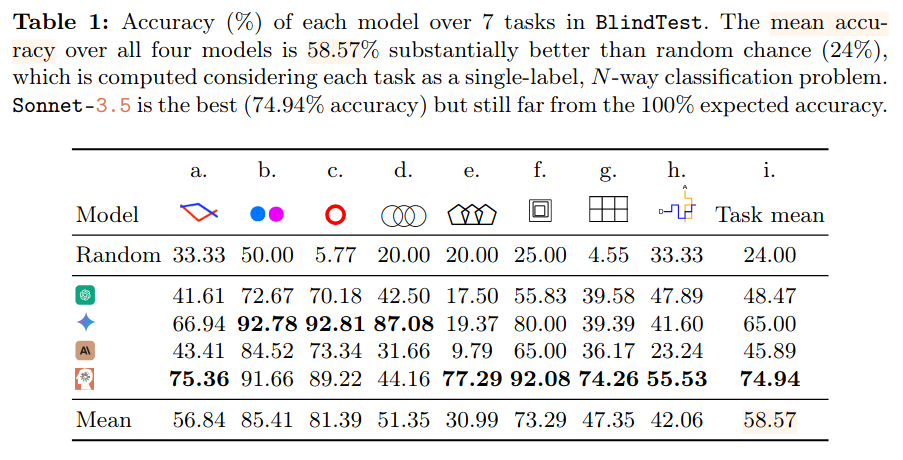
TL;DR
The recent trend is to equip Large Language models with vision capabilities and creating Visual Language models (VLM). However, it’s unclear how well VLMs perform on simple vision tasks. This paper introduces “BlindTest”, a benchmark of 7 simple tasks, such as identifying overlapping circles, intersecting lines, and circled letters. The results show that VLMs achieve only 58.57% accuracy on average, far from the expected human accuracy of 100%.
Task example
The paper aims to investigate how VLMs perceive simple images composed of basic geometric shapes. This study serves as a proxy to answer the broader question: “Do VLMs perceive images like humans do?” To this end, the evaluation tasks feature images with simple geometric shapes.

How this benchmark differs from existing onces
VLMs are powerful such that describing unusual activities in an image (e.g. a man ironing on a moving taxi) has become a standard sanity check.
Existing VLM benchmarks cover a wide range of topics but only measure the overall performance gap between humans and LLMs, without identifying specific limitations for future research. Additionally, many benchmarks allow answers to be inferred from the question and choices alone or are memorized by VLMs from their large-scale training.
The ARC benchmark also consist of abstract images composed of simple shapes, but it challenges VLMs to reason based on those patterns.
Authors’ insights
- VLMs excel in humans’ eye exams, which typically feature single, separate symbols.
- BlindTest benchmark reveals that some chat interfaces perform worse than their API counterparts, possibly due to extra fine-tuning or specific system prompts that align VLMs with company policies.
- LLMs perform similarly across three image sizes.
- The late-fusion mechanism may cause VLMs to extract visual features without considering the question, leading to “blindness”. If a model knows the question asks it to focus on a specific area, it might extract accurate visual information to answer simple questions.
- VLMs are biased towards the well-known 5-circle Olympic logo.
Limitations
- Most VLM models use visual embeddings that training process did not include BlindTest similar tasks: The most popular visual embeddings is CLIP which was trained on image captions.
- Tests may not be generalizable, and VLMs that successful on these tasks might not guarantee they will “see” other low-level features.
- It’s unclear if the authors tried multiple inferences of the same prompt to ensure consistent results.
- Recent methods, such as “chain of thought”, might improve benchmark performance by carefully crafting the prompt.