TL;DR
Existing diffusion models for sequence generation have two main limitations: They either generate sequences one token at a time, without the ability to steer the sampling process towards desired outcomes, or diffuse the entire sequence iteratively but are constrained to a fixed sequence length. Diffusion Forcing combines the benefits of both approaches by diffusing the entire sequence iteratively with independent per-token noise levels that are conditioned on the previous token in the sequence.
Method
Next token prediction and entire sequence diffusion can have a unified view.
- Masking along the time axis: Training next-token prediction with teacher forcing is equivalent to masking each token at time t and making predictions based on past tokens x1:t−1.
- Masking along the noise axis: Full-sequence forward diffusion can be seen as a form of partial masking, where noise is gradually added K times to the data until x_K_{1:T} becomes pure white noise, loosing the original information.
Diffusion Forcing is a framework for training and sampling sequences of arbitrary length with noisy tokens
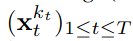 A key innovation is that the noise level (k,t) of each token can vary: each token in the sequence has a hidden state that is updated when a new noisy observation is made. The hidden state is updated using a recurrent neural network (RNN) in a Markovian fashion, meaning that it only depends on the previous token in the sequence.
A key innovation is that the noise level (k,t) of each token can vary: each token in the sequence has a hidden state that is updated when a new noisy observation is made. The hidden state is updated using a recurrent neural network (RNN) in a Markovian fashion, meaning that it only depends on the previous token in the sequence.
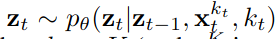
The diffusion process then is preformed along the two axes: time and noise level.
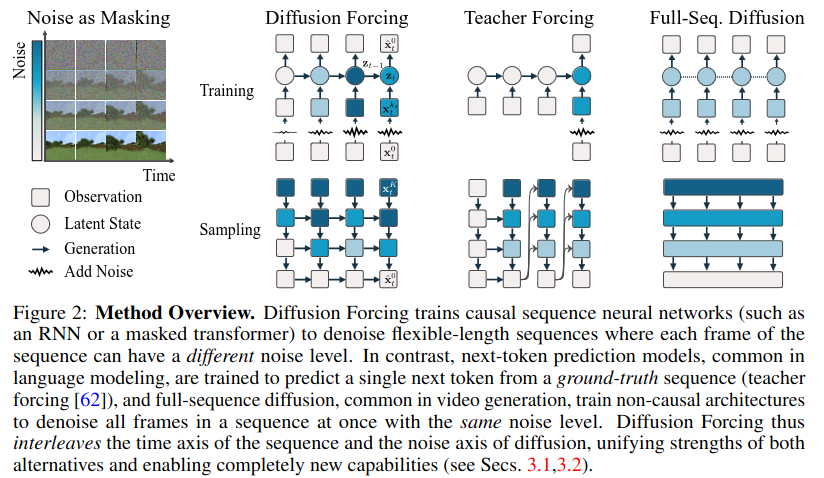
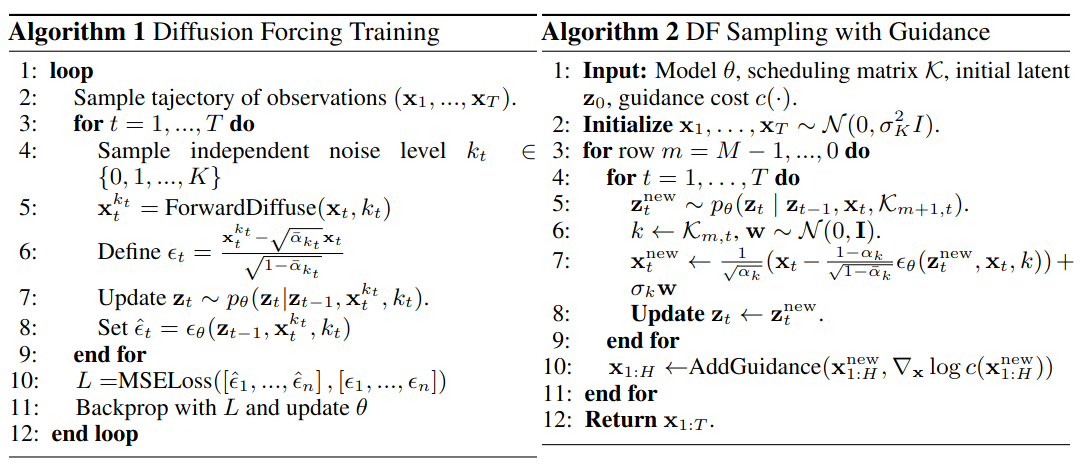
Limitations
- The current implementation relies on a simple Recurrent Neural Network (RNN), which may not be sufficient for more complex tasks. It would be interesting to explore whether the method can be scaled up to more powerful architectures, such as Transformers and how the RNN model can take into account hidden state of previous tokens.
- Compared to next token prediction methods, Diffusion Forcing introduces an additional hyperparameter: the number of diffusion steps to perform along the noise axis.
- Using the proposed method in text generation tasks, it is unclear how to determine the optimal sequence length. Unlike next token prediction methods, which can predict a special “EndOfSequence” token to indicate completion, Diffusion Forcing may not provide a clear signal for when a sentence is complete. This can lead to incomplete sentences or require additional sequence generation to complete the thought.