Last week I attended the CVPR conference, a gathering of computer vision researchers and professionals showcasing the latest advancements in the field. Some interesting recent trends:
- Multimodal models and datasets
- Large Language Models (LLMs) are being used to train vision models
- Images are used to ground LLMs, reducing their hallucination
- Models are being fed with both images and videos to achieve better results
- Foundation models are commodity
- These models are becoming more accessible and less expensive to create
- They are trained on multiple modalities and tasks (even for a very niche tasks like hand pose estimation)
- Transformers are everywhere: While not a new trend, it’s still notable that attention mechanisms are incorporated into almost every model.
Talk summary
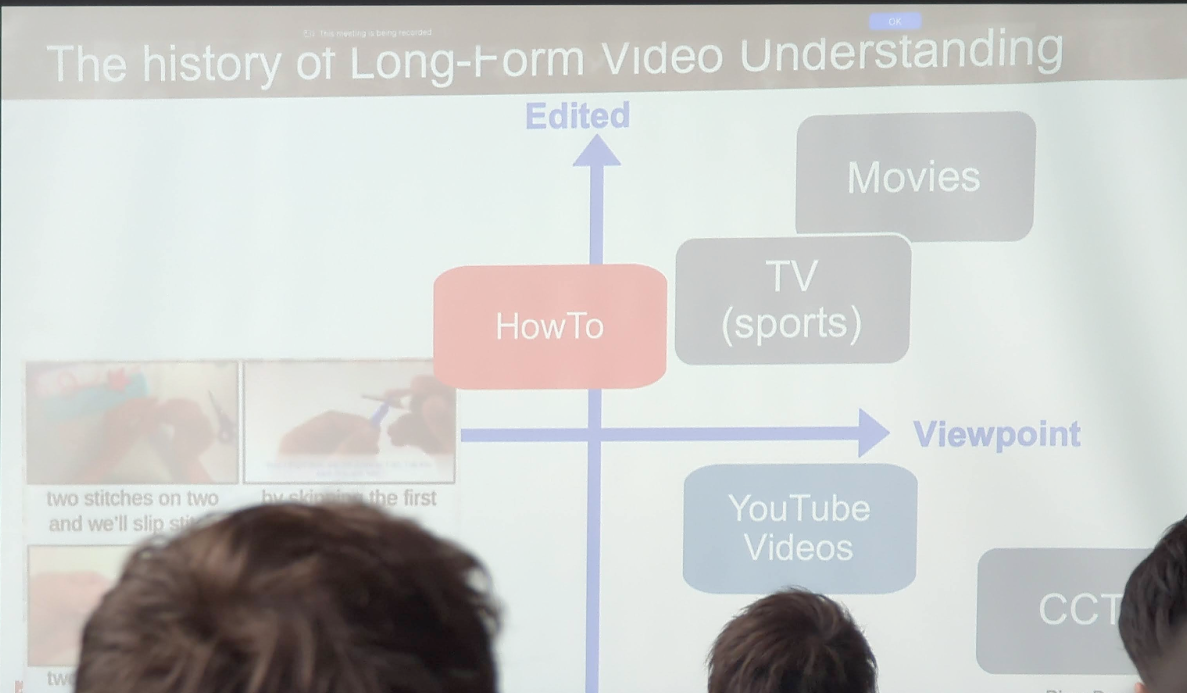
Long Form Video Understanding, Dima Damen, Google Brain
There are two main types of videos:
- Viewpoint Videos: Unscripted daily activities (e.g., Ego4d).
- Edited Videos: Movies and TV shows, with varying degrees of editing.
Audio can help in understanding videos and editing can help break down videos into shorter clips.
Challenge #1: Lack of Semantic Alignment in Egocentric Videos. Solution: Descriptions provided by participants and experts, with three levels of semantic annotations: actions, performance, atomic descriptions.
Challenge #2: Missing Semantic Temporal Alignment. Solution: Joint training of classifiers for action identification and time prediction using both video and audio annotations. Fusion model combining audio and video with separate encoders for each modality.
Challenge #3: Head Movements in Egocentric Videos. Solution: 3D reconstruction to create a global representation of the space.
Additional Insights:
- A proxy task of counting repeating actions using latent vectors improves generalisation.
- Moving towards processing long videos with batch size = 1 without shuffling or IID assumption. Non-standard optimizers like RMSprop without momentum work better.
- In the Q&A, a discussion highlighted that babies might learn through shuffling information in their sleep, suggesting that removing the IID assumption might be too rigid.

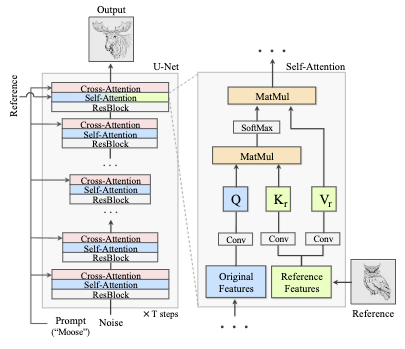
Visual Style Prompting with Swapping Self-Attention
Changing the style of images generated by diffusion models while preserving content is challenging.
Common methods:
Using text prompts to describe style. Limitation: Text fails to adequately capture style.
Use a reference image to control style. Issue: Content leakage from the reference image into the generated image.
 The authors suggest to swap the key and value features of self-attention block in the original denoising process with the ones from a reference denoising process.
The authors suggest to swap the key and value features of self-attention block in the original denoising process with the ones from a reference denoising process.
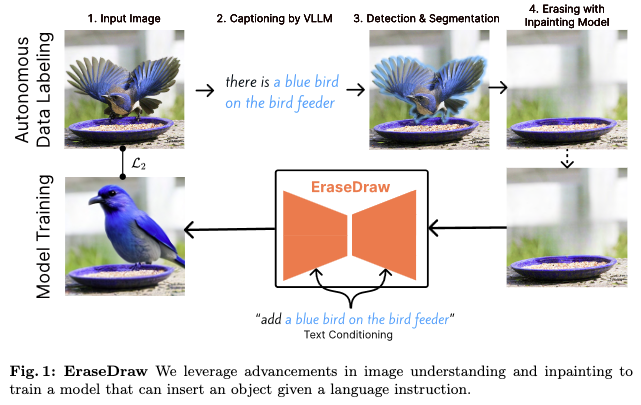
EraseDraw: Learning to Insert Objects by Erasing Them from Images
There are no good computational models that insert objects realistically to images, they often place them incorrectly or with poor lighting. However, current models are good at removing objects and backgrounds from images.
By reversing the object removal process, the speakers created high-quality data to teach models how to insert objects. Using this data, they trained a text-conditioned diffusion model.
Ecommerce Multimodal Foundation Models: Raffay hamid
Foundation models are designed to handle various downstream tasks such that they can be applied in e-commerce to improve customer experience and product placement.
An important aspect of such models is they can bridge different data types and modalities, such as text (customer queries) and product information (price, title, rating, videos).
Multimodal are trained on the following tasks: Image-text retrieval, Visual reasoning, and Multimodal representation learning and alignment (e.g., CLIP).
Challenges and Solutions:
- Multimodal Alignment: Finding common code spaces to integrate different modalities.
- Vision Language Pretraining: Addressing intra-modality coherence by introducing more tasks.
- Video Language Alignment: Developing complex architectures for video-caption alignment due to the lack of datasets.
#1 Online Shopping Use Cases
- Image-based product search: This enabled multimodal search for specific needs (e.g., “shirt for wedding” or “shirt for office”).
- User-generated content (UGC) recommendation
- Related product recommendations
- Conversational search (shopping assistant)
#2 Video Ads and Product Placement
- Video ads can disrupt customer experience.
- Product placement during movies as a less intrusive alternative.
- Dynamic product changes in scenes for relevant advertising.
There’s a risk for product placement of brand safety. Need to ensure the placement is in non-violent scenes


How I stopped afraid of foundation models: Yossi Keller
Training foundation models can be very expensive. However, foundation models are not just about having huge models but having a model that serves multiple tasks. Such models can leverage efficient architectures and be quite cheap.
Insights:
- Attention is widely used in any new method. They are less useful for tasks like face recognition where images are already well-aligned.
- Decoder-Only architecture is a more efficient approach for utilizing attention.
- A shared embedding space for prompts and targets improves model performance.
- A cross-modality decoder models better the interaction between different types of data.
An example of a good foundation model: Segment Anything.
- Developing an embedding layer that can handle simple prompt inputs like bounding boxes and points.
- Highlighting the correlation between different prompts to improve model learning.


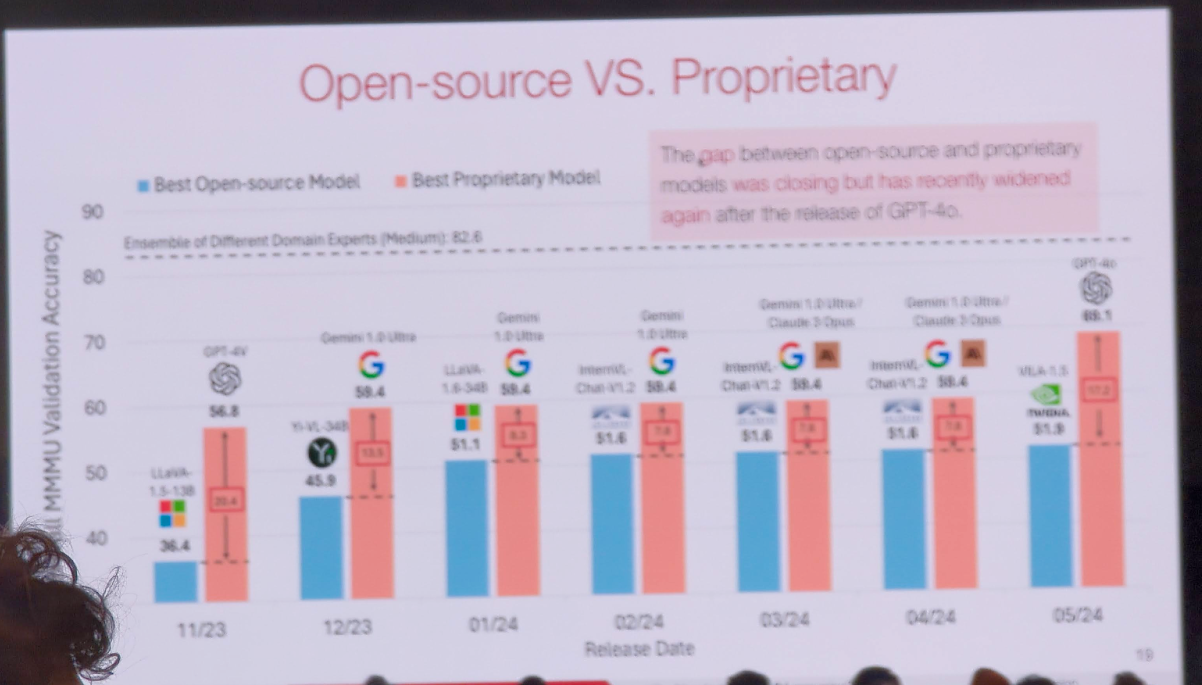
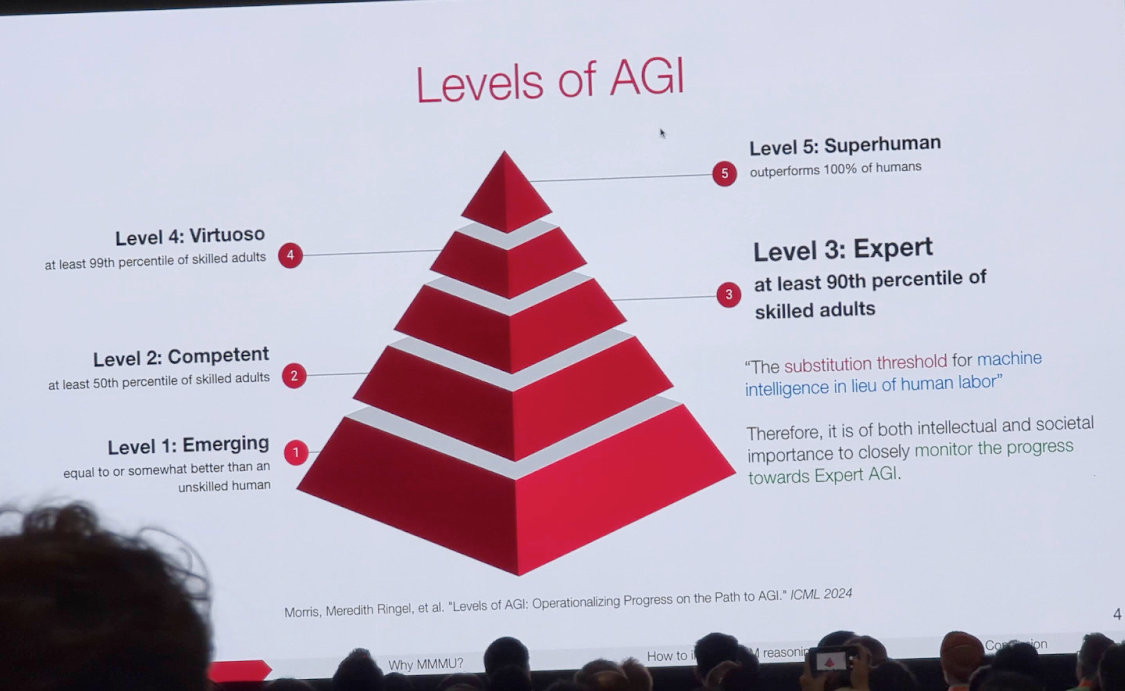
A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Current multimodal benchmarks are too simplistic to evaluate artificial general intelligence (AGI) effectively, particularly AGI that is comparable to a human expert, which requires both breadth and depth of knowledge.
New Benchmark Proposal
- The speaker introduced a new benchmark designed to evaluate multimodal models on college-level tasks requiring advanced reasoning and domain-specific knowledge.
- Dataset includes 11.5K multimodal questions from six core disciplines (e.g., Art & Design, Business, Science).
- This benchmark aims to challenge models similarly to human experts and is already widely used in the industry.
Performance and Improvement
- Evaluation of open-source models and advanced models like GPT-4V and Gemini showed they still lag behind human experts.
- Knowledge is crucial for enhancing perception and reasoning in models.
- Improving model reasoning involves using high-quality synthetic data and developing larger models.
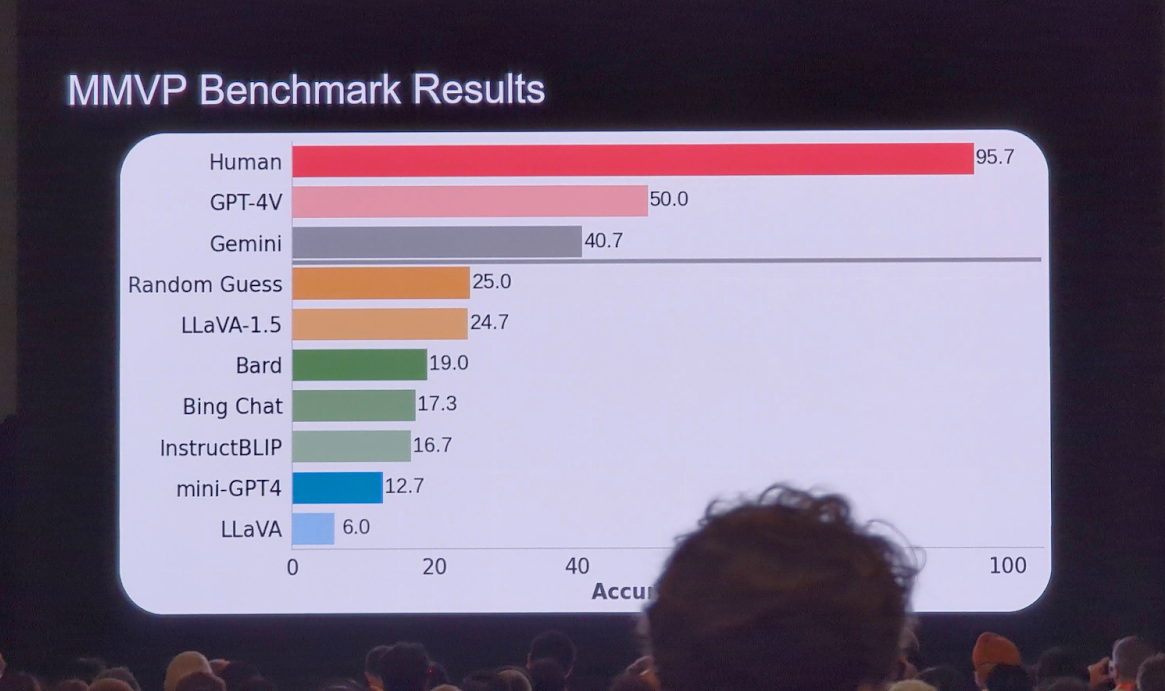
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Multimodal models make unexpected mistakes in tasks such as counting objects (how many wheels are in the image) and determining object composition (whether the object is in the left or in the right)
A main source of the issue is the CLIP model that is widely used to encode images in Multimodal models.
CLIP-blind pairs: images that CLIP perceives as similar despite their clear visual differences
Creating a dataset:
- Asking a question regarding choosing one image out of two, if the two images are encoded to the same vector by CLIP, the prediction is probably wrong.
- From the images of (1), ask annotators to describe the differences between the images.
- Creating a benchmark.
Interestingly, random guessing is better than many models.
Understanding mistakes: Using questions and summarising patterns with ChatGPT to understand why models make specific errors.
To reduce the issue, use CLIP and DINO embeddings to encode images.


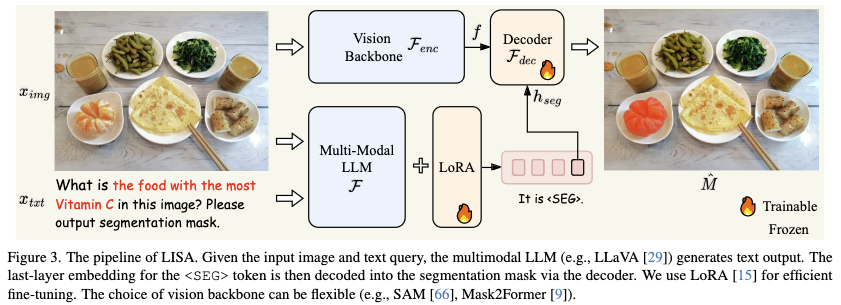
LISA: Reasoning Segmentation via Large Language Model
A new task called reasoning segmentation, which aims to
- Expand semantic segmentation vocabulary to handle expressions like “the lady with the blue shirt.”
- Extend referring expressions to include arbitrary, reasoning-based queries, such as “who is the president of the United States in the image.”
Method:
- Add SEG token to LLM vocabulary.
- Create a dataset of Q&A along with segmentation masks.


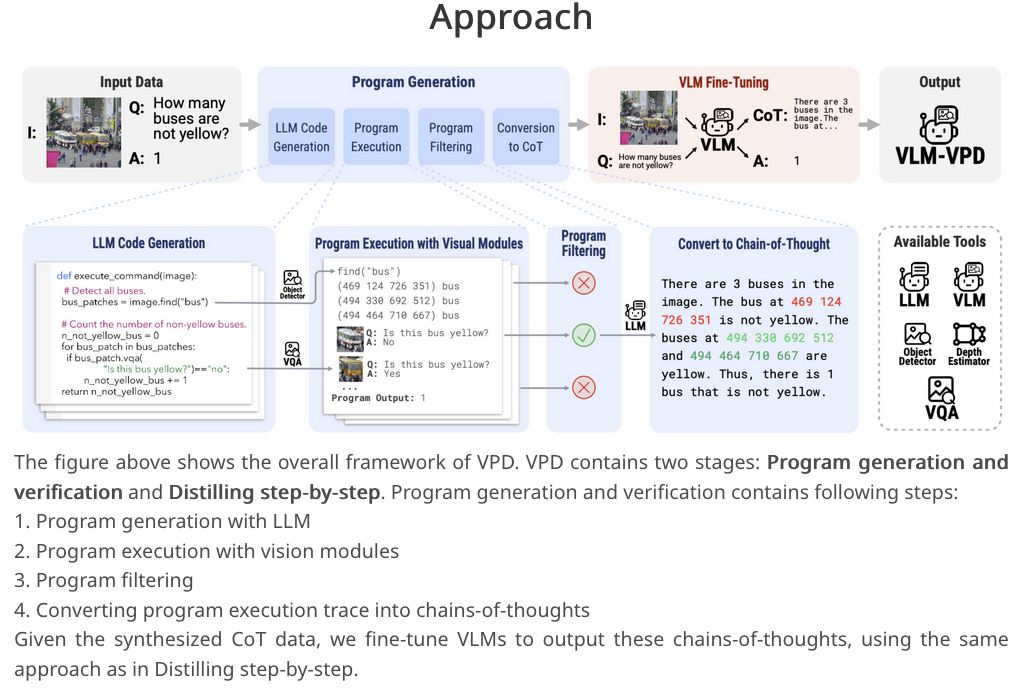
Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models
Multimodal models struggle with tasks like counting and understanding spatial relations.
Existing approaches involve using LLMs to generate programs that utilize specialized vision models, but are not scalable and incurs high latency due to multiple model loading.
The suggested approach is:
- Using LLMs to generate multiple candidate programs for a task.
- Executing and verifying these programs to identify the correct one.
- Translating the correct program into a language description of reasoning steps.
- Distilling these steps into a Vision-Language Model (VLM).
In inference there’s no code generation, no tools and only one model inference.

Real World Spatial Co-Pilot, Marc Pollefeys, Microsoft
Create an AI co-pilot to scale expert knowledge: It aims to teach complex procedures to people in scale.
The main hardware is HoloLens. It contains Depth camera, RGB cameras, hand tracking, gaze tracking, microphones for spatial audio, and custom chip for real-time processing.
An example of a use case: A user asks a question regarding a task in the real word then HoloLens highlights the part of the scene that is relevant.
Technology and Methods:
- Multi-device mapping and localization using cloud processing.
- Extending CLIP to include geometry for semantic understanding.
- Using Neural Radiance Fields (NERF) for 3D object prediction.
Data Collection Approach:
- The data collection focuses on recording how a person is taught to perform a task, rather than just how it is done.
- Data include high-level and fine-grained instructions along with corrections.

Poster summary
Making Large Multimodal Models Understand Arbitrary Visual Prompts: Allowing multimodal models understand arbitrary visual prompts via directly overlying the visual prompts onto the original image.

Tune-An-Ellipse: CLIP Has Potential to Find What You Want:

Multi-Modal Hallucination Control by Visual Information Grounding. From their abstract: To reduce hallucinations, we introduce Multi-Modal Mutual-Information Decoding, a new sampling method for prompt amplification. M3ID amplifies the influence of the reference image over the language prior, hence favoring the generation of tokens with higher mutual information with the visual prompt.
TextCraftor: Your Text Encoder Can be Image Quality Controller: Synthesising an image that aligns well with the input text still requires multiple runs with carefully crafted prompts to achieve satisfactory results. This work aims to improve the text encoder: They found that, instead of replacing the CLIP text encoder used in Stable Diffusion with other large language models, they can improve it via fine-tuning.
Scaling Up Video Summarization Pretraining with Large Language Models. Creating a dataset for video summarization by transcripting videos and ask LLM to summarise them.
