Andrej Karpathy has released a great series of in-depth-hands-on of building GPT models. Here are my notes taken during watching the “Let’s build the GPT Tokenizer” video.
What are Tokens?
Large Language Models (LLM) don’t process the raw text directly. They use tokens are the out of the Tokenization process which translates text into sequence of tokens. Many issues of LLMs are mainly due to tokenization:
- LLMs are bad at simple arithmetic.
- LLMs perform poorly with non-English languages.
- LLM can’t do simple string manipulations like reversing a string.
Example of Tokenization
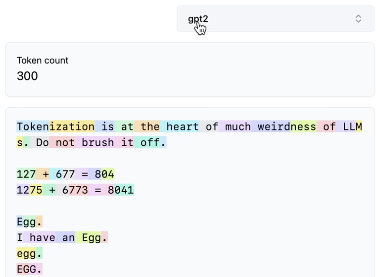
An example of tokenizing text to words is shown below, each token is shown in a different color. Notice spaces are part of the tokens!
Some weirds phenomena of the Tokenization process:
- The number “127” is tokenized as a single token, whereas “677” is split into two tokens.
- The tokens for " Egg" (with a space) and “Egg” (without a space) are different.
- In Python, every space is treated as a separate token, which can cause the context length to overflow if there are many spaces.
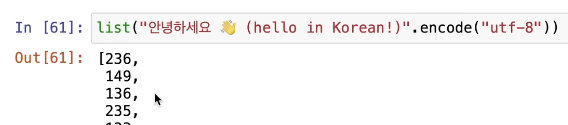
- Non-English sentences are tokenized into more tokens, reducing the effective context length the LLM can handle.
Creating a Tokenizer
The common paradigm to represent characters in text is using the Unicode format. To convert Unicode to a byte-string, several encoding methods exist, with UTF-8 being the most common. However, using UTF-8 naively limits us to only 256 tokens (the maximum number a byte can represent), which is insufficient and would result in excessively long context lengths. The solution to this problem is “Byte Pair Encoding” (BPE).
Byte Pair Encoding
The process of Byte Pair Encoding is as follows.
- Encode the input text using UTF-8, starting with 256 initial tokens.
- Identify the most frequent pair of tokens and replace it with a new token.
- Repeat step 2 iteratively until a predefined condition, such as the desired number of tokens in the vocabulary, is met.
An important metric for evaluating tokenizer is the compression ratio: (the text length in characters) / (the text length in tokens). A higher compression ratio indicates that the LLM can handle a longer context length.
Regex Patterns
To ensure tokens retain their semantic meaning, certain patterns should not be merged, e.g., ‘dog.’, ‘dog!’ and ‘dog?’ should remain separate tokens. In the GPT-2 code, additional merging rules are enforced to prevent such merges. These rules are implemented using regular expressions (regex). Some of the rules are:
- Not merging sequences with space between.
- Numbers are not merged with letters.
- The character ’ splits tokens.
- White spacing are included in the beginning of the words (" are").
- Punctuations are grouped together
The implementation first splits the input string into a list based on these regex rules, then applies byte pair encoding so that different elements in the list cannot be merged.

Special Tokens
There are 256 raw byte tokens. GPT performs 50,000 merges, resulting in a total of 50,256 tokens in the vocabulary. Additionally, there is and additional special token: ‘<|endoftext|>’, used to delimit documents in the training set. This token hints the LLM to ignore previous tokens before the special token when predicting the next text.
When doing finetuning LLMs, many special tokens are introduces to provide more context to the model: browser interactions, chat responses, etc.
- Add an additional row to the embedding matrix (each row represents a specific token) to be fed into the LLM.
- Extend the final layer of the LLM to predict the new token.
Usually, fine-tuning involves training only the new parameters associated with the additional tokens while keeping the rest of the model parameters frozen.
Vocabulary Size Tradeoffs
Vocabulary size impacts two aspects of LLM architecture:
- The number of rows of the token embedding table, where each token is associated with a row trained via backpropagation.
- The last layer assigns a probability to each token in the vocabulary, requiring more probabilities as the vocabulary size increases.
There’s a sweet spot of vocabulary size. While a larger vocabulary reduces the number of tokens needed to encode a sentence and effectively increases the context length, it also increases the size of the embedding table and the complexity of the SoftMax function which has negative impact on the computational requirements. In addition, tokens become rarer during training, leading to under-trained vectors.
Multi-modality
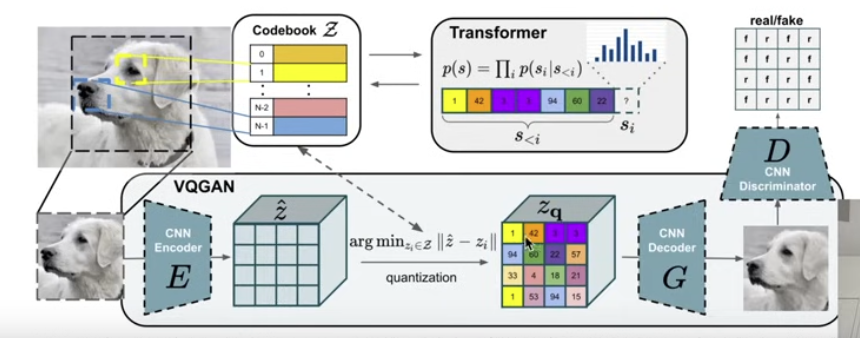
Recent transformers can process both images and text, producing either type of output. Many methods involve feeding images into a pre-trained visual encoder, then applying quantization to convert them into integers, which are used as tokens alongside text tokens.
Additional Insights from Andrej
- In deep learning, it is preferable to keep the raw data intact without text normalization. This better represents real-world distribution and enable the model to learn nuance representations.
- Characters not present in the training set should fall back to UTF-8 bytes. Without this fallback, we might get many ‘unknown’ token at inference stage.
- Llama2 uses a tokenizer that adds a space (’ ‘) at the beginning of every sentence, so ’ hello’ and ‘hello’ map to the same token.
- Ending a sentence with a space negatively impacts the model’s completion accuracy since ’ ’ is encoded as a token. In real-world usage, most completions include ’ ’ rather than just a space.
Resource
sentencepiece: A common tokenization library. It was used in Llama2 but it’s not very recommended by Andrej since it has too nuance settings.
tiktoken: A library for producing GPT4 tokens. It contains the encoder and decoder but doesn’t have the tokenizer training code.
minmbpe: Andrej’s Tokernizer library to train, encode, and decode text.