TL;DR
In self-supervised learning there are no guarantees that representations will organize the clusters according to their semantic classes. When labels are partially available the authors propose to replace the cluster centroids with class prototypes learned with supervision. In this way, unlabeled samples will be clustered around the class prototypes, guided by the self-supervised clustering-based objective.
Method
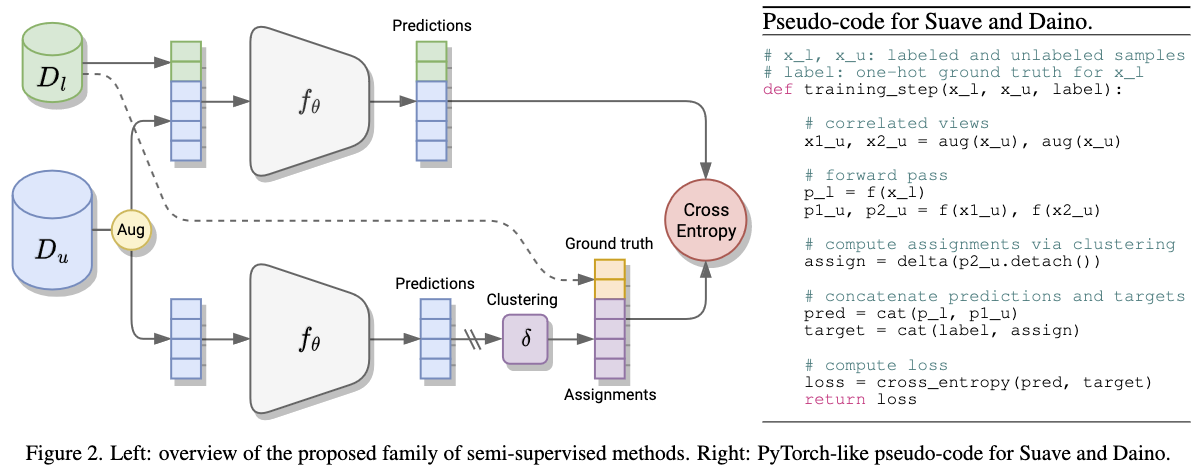
The method trains a model by jointly optimize a supervised loss on labeled data and a self-supervised loss on unlabeled data using the same loss function (cross-entropy).
Learning with unlabeled data
Given two correlated views (x,x^) of an input image:
- Feeding the images to an encoder. with an additional bias-free linear layer to produce the feature vectors (h, h^).
- Create a clustering assignment of h^ by applying the softmax function. This acts as the pseudo-label y^.
- y^ is used as the target label in the cross-entropy loss for softmax(h). A stop-gradient operation is performed to not propagate gradients through the pseudo-label.
Some notes:
- The length of h and h^ is equal the number of clusters and the number of clusters is pre-defined.
- The cluster assignment is not needed: The difference between h and h^ can directly be used as the loss function. However, the clustering helps to prevent collapsing of the representation (where all samples are assigned to the same cluster).
- Intuitively, the loss leverages cluster assignments as a proxy to minimize the distance between latent representations (h, ˆh). As a by-product, the objective also learns a set of cluster.
Leveraging labeled data
By learning with unlabeled data only there are no guarantees that representations will organize the clusters according to the class labels.
With annotated data, the pseudo-label can be replaced with the ground-truth label when available:
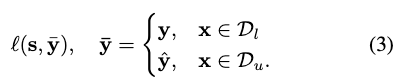 where y is the ground truth label and y^ is the pseudo label.
where y is the ground truth label and y^ is the pseudo label.
Since the authors balance the labeled and unlabeled loss by 1:1, implementation wise they concatenate the labeled with the unlabeled samples and the pseudo labels with true labels. Then they feed them to the same cross entropy loss.
Limitations
- It’s not clear it the method works when there are some classes with no labeled samples. Potentially, this classes can be spread across clusters with not meaningful semantic separation.
- There is a hidden hyperparameter of balancing the labeled and unlabeled loss. In the paper, the authors assume it’s 1 without explicitly mention and discuss it. The method is probably sensitive for this hyperparameter
Resource
Arxiv: published in CVPR 2022