TL;DR
Generative Large Language Models (LLMs) are limited to generate text based on their training data which means any extension to additional sources necessitates additional training. Retrieval Augmented Generation (RAG) is a method that combines the use of a database with LLMs enables updating the LLM knowledge and make it more precise for specific applications.
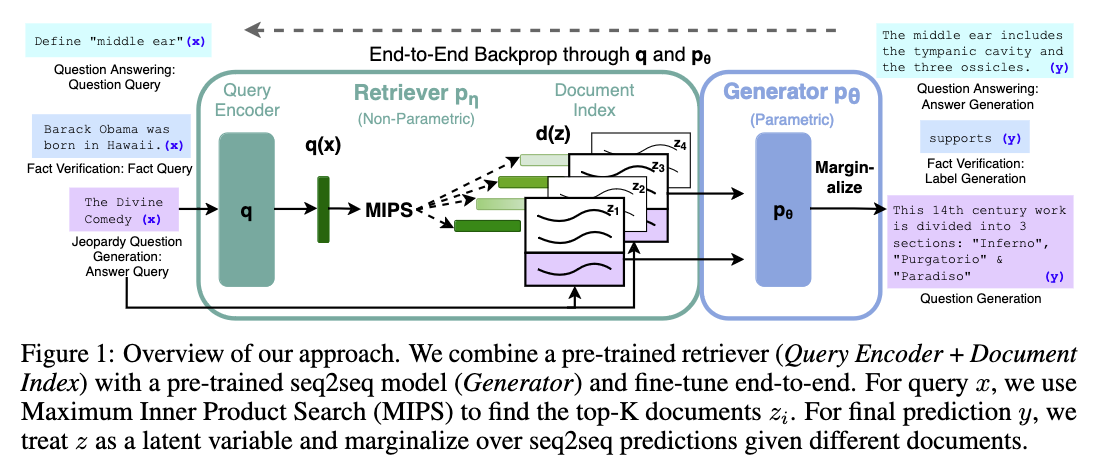
Method
Building blocks
The method consists of 3 building blocks.
- Document index. A pre-trained model was used to encode documents into embeddings to create the index. In the paper, the authors ues BART trained on TriviaQA answers.
- Retrieval. A query (e.g. a question) is encoded using a BART model similar to (1) with the difference it was trained on questions part of TriviaQA. Then the top k most relevant documents from the database are retrieved. Relevance is determined by the maximum inner product between the query and document embeddings.
- Text generation. To generate the answer, the query is concatenated with a retrieved document and then inputted into another Language Model (a seq2seq transformer). The generator then calculates the output sequence probability for each document. To produce a final answer, the output probabilities are marginalized over the K documents.
Marginalized over the K documents:
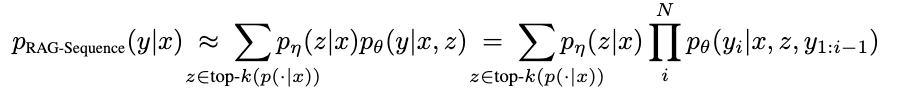
Training procedure
The retriever and generator are jointly fine-tuned on input/output pairs, without a direct supervision of the retrieved documents.
Notice that updating the document encoder is expensive as it requires periodic updates to the document index. The authors found that this step wasn’t needed for achieving high performance, so they kept the document encoder and index static, only the query encoder and the BART generator were fine-tuned.
Limitations
- Despite the generator’s use of a database, it can still hallucinate responses. This makes its answers untrusty.
- The authors utilized a seq2seq transformer for generating answers. However, a more efficient strategy might be to use the embeddings directly. This would only require only a decoder model, rather than a seq2seq transformer.
Resource
Arxiv: published in NeurIPS 2024
A Practical Guide to RAG Pipeline Evaluation (Part 1: Retrieval)