TL;DR
Vision-language models (as CLIP) are frequently used as zero-shot classifiers: Given a text prompt, one can find the prompt similarity to image embeddings. Prompt engineering is able to improve this zero-shot classification significantly, however, it’s time consuming. The CoOp method suggests to have a learnable prompt (trained with a single sample .i.e. one shot) and by that get similar performance to human crafted prompts. By using 16 samples, they able to improve human created prompts by +15%.

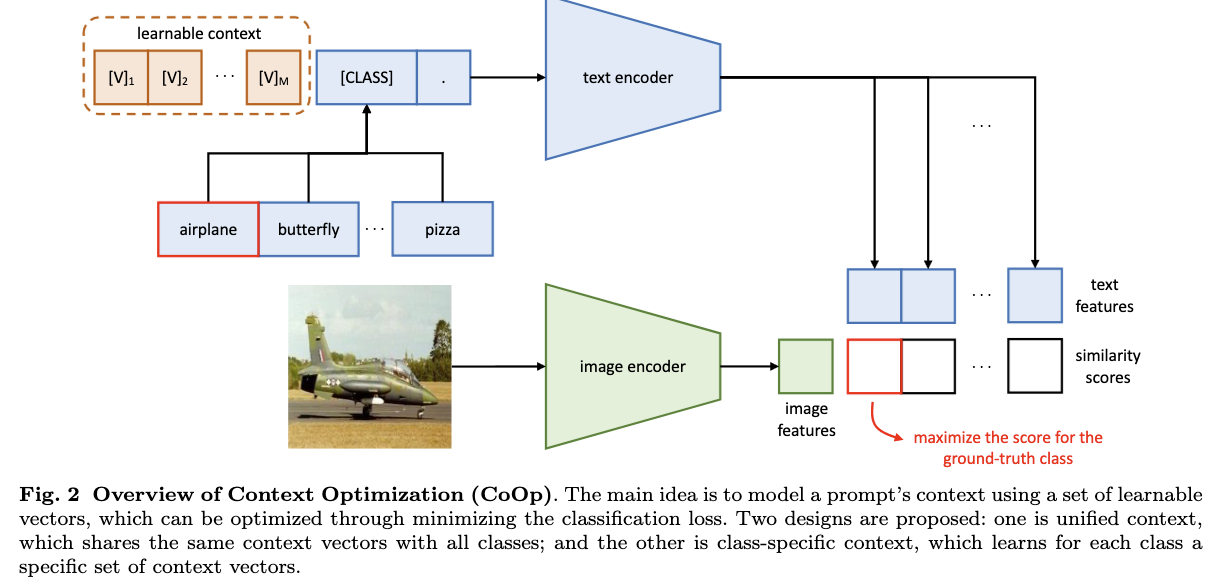
Method
The authors suggest the “Context Optimization” (CoOp) method: Replacing the prompt’s context words with learnable vectors, which
are initialized with either random values.
Two implementations are provided to handle tasks of different natures:
Unified context shares the same context with all classes and works well on most categories;
At inference, feed the text encoder with a single context vector, and get a prediction of the trained classes
class-specific context learns a specific set of context tokens for each class and is found to be more suitable for some fine-grained categories.
At inference, feed the text encoder with “n_cls” of vectors and get a prediction of each class.
During training, the prediction errors is minimized using the cross-entropy loss with respect to the learnable context vectors while keeping the pre-trained parameters (CLIP) fixed: Gradients are back-propagated all the way through the text encoder.
Unified context vs class-specific context from the paper’s github:
# random initialization
if cfg.TRAINER.COOP.CSC:
print("Initializing class-specific contexts")
ctx_vectors = torch.empty(n_cls, n_ctx, ctx_dim, dtype=dtype)
else:
print("Initializing a generic context")
ctx_vectors = torch.empty(n_ctx, ctx_dim, dtype=dtype)
nn.init.normal_(ctx_vectors, std=0.02)
Limitations
- It’s not zero-shot per say, still requires training of the context vectors.
- The task of “whether the class exists in the image” is not straight forward using this method: the method trains to classify the image to one of a closed set of classes, and not able to indicate when non of the classes are present in the image.
Resource
Arxiv: published in International Journal of Computer Vision (IJCV)