TL;DR
Control Net is a framework designed to control the content of images generated by diffusion models. The process involves taking a trained diffusion model, freezing its weights, cloning some of its building blocks, and training the cloned weights with a conditioning input image.

Method
Architecture. Given a trainable diffusion model, the Control Net model is created by:
- Freezing the parameters of the original model.
- Cloning some of the original model blocks to a trainable copy. The trainable copy takes an external conditioning vector c as input.
- Connecting the trainable copy to the locked model with zero initialized convolution layers.
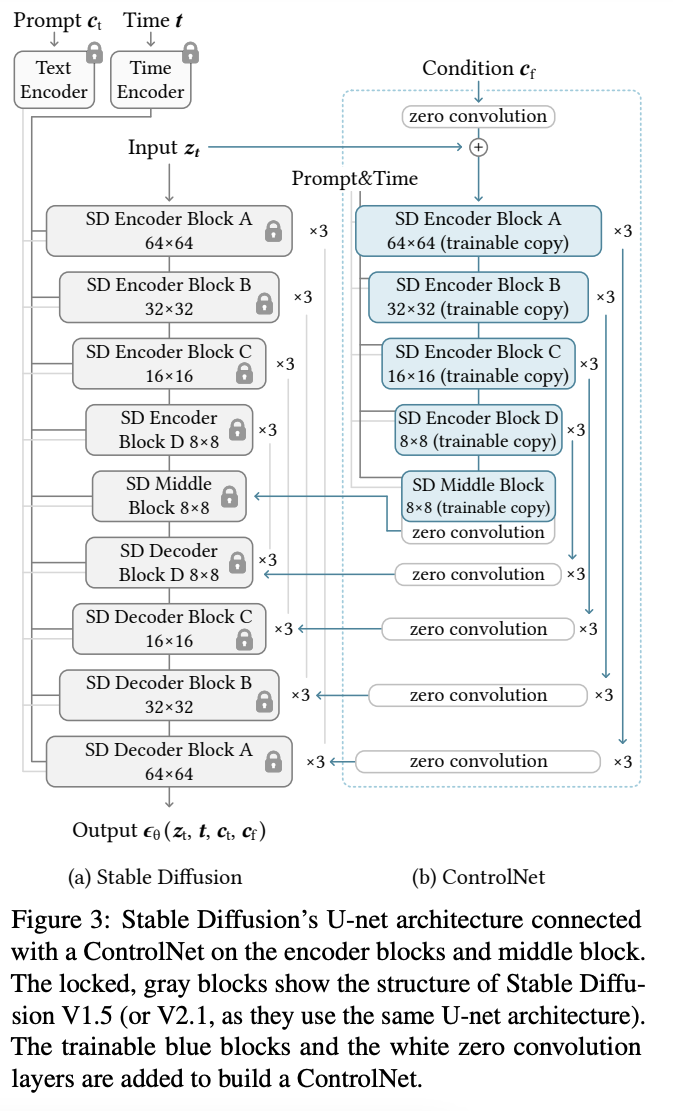
Training process. Control Net requires training for every new input conditioning signals:
Given an input image z0, image diffusion algorithms progressively add noise to the image and produce a noisy image zt, where t represents the number of times noise is added.
Given a set of conditions including time step t, text prompts ct, as well as a task-specific condition cf, image
diffusion algorithms learn a network ϵθ to predict the noise added to the noisy image zt with
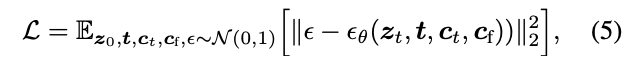
Some small details:
- In the training process, the text prompts are sometimes replaced with empty strings. This better aligns the generated images to the input conditioning images (e.g., edges, poses, depth, etc.) as a replacement for the prompt.
- Since the original parameters are frozen, no gradient computation is required which saves CUDA memory.
- For Stable Diffusion (as a latent diffusion model), there’s a need to first convert each input conditioning image from an input size of 512 × 512 into a 64 × 64 feature space vector that matches the size of Stable Diffusion. This is done a model consists of 4 layers.
Limitations
- Control Net is x2 the size of the pre-trained diffusion model. This requires more GPU memory.
- There’s a need of train the copied model for each new conditioning input image.