TL;DR
The process of video editing can be time-consuming and laborious. Many diffusion-based models for videos either fail to preserve temporal consistency or require significant resources. To address it, the “RAVE” method incorporates a clever trick: it takes video frames and combines them to a “grid image”. Then, the grid image is fed to a diffusion model (+ControlNet) to produce an edited version of the grid image. Reconstructing the video from the edited grid image results in a consistent edited temporal video.
Proof-of-Concept
I’ve tested the method with videos from Amazon (my code fork).
Prompt: “A zoom in of an handbag laying on the floor”.
ControlNet conditioning: “softedge_hed”.
Prompt: “A clown with red hat walking on the runway in a fashion show”
ControlNet conditioning: “softedge_hed”.
Preliminaries
The method utilizes two key building blocks.
1. ControlNet. A control mechanism for diffusion models by integrating a weight locking strategy, allowing for additional conditions beyond the text prompt (depth, pose, and surface normals).
2. The grid trick (character sheet). Feeding the diffusion models with a grid of images. The resulting output maintains the grid format during the editing process which produces consistent styles.
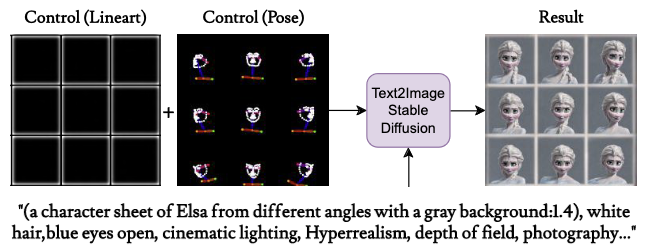
Method
- Extract video frames and apply the condition pre-processor (similarly to ControlNet).
- Apply video2grid(): Creating an image using a grid of NxN frames (The authors used 2x2 and 3x3 frames). This grid is applied both for the conditioning frames (Condition Grids) and latent diffusion images (Latent Grid).
- De-nosing steps. For t in 1 to T:
- Apply shuffle(): Randomly rearranging the locations of the frames across the grids. This encourages spatio-temporal interaction between the frames.
- Feeding the grids, Condition Grid and Latent Grid, to the Unet model.
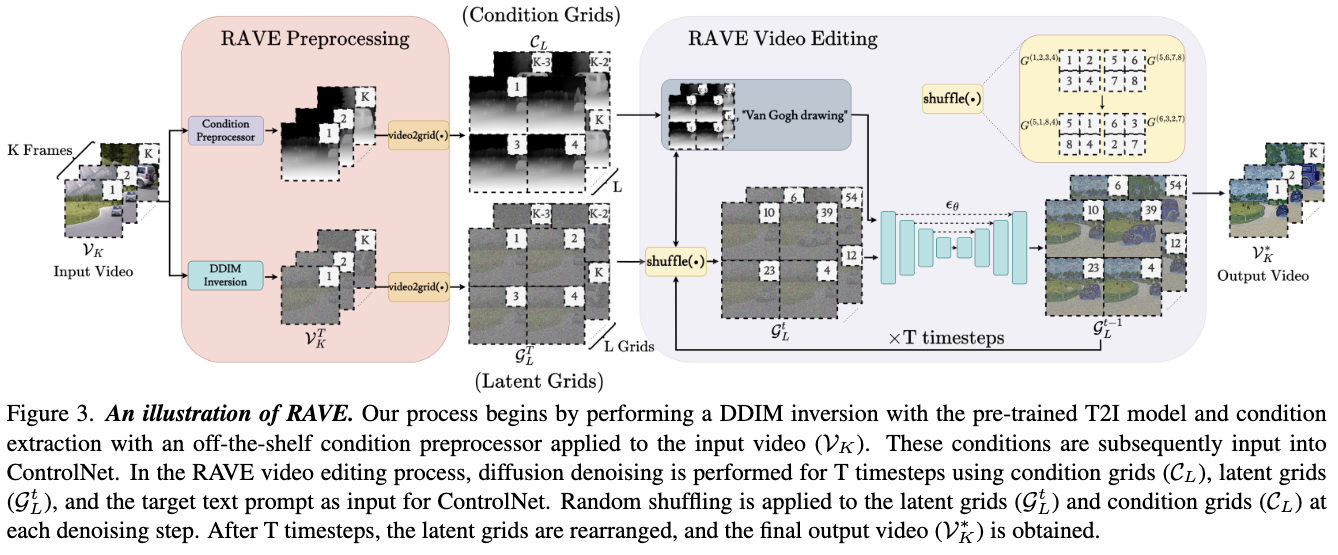
Design choices
Applying the grid trick directly to videos naively (create a giant big grid) cannot fit the GPU therefore the sub-grids approach is memory efficient.
Additional novelty
The paper also provides a video evaluation dataset the includes object-focused scenes, human activities like dancing and typing, and dynamic scenes featuring swimming fish and boats.
Limitations
Using the grid trick, the output image is with lower resolution. To up-scale it, there a need for additional compute (usually done be a different convolution network).
The authors say that that the applied the initial grid and preserve the original frame order. This seems unnecessary since right after that the shuffle function is applied.
Resource
Denoising diffusion implicit models (DDIM): A method of accelerating the sampling process of diffusion model.