TL;DR
Direct Preference Optimization is a method of fine-tuning Large Language Models (LLM) to better align their outputs with human preference. It’s used as a simpler alternative to RLHF since it can be directly applied to the model without needing a reward function nor reinforcement learning optimization.
Method
The authors propose to re-parameterize the reward model of RLHF to obtain the optimal policy in closed form. This enables to solve the standard RLHF problem using a simple classification loss.
To align with human preference, DPO requires the following steps:
- Train an LLM with unsupervised data.
- Given a prompt, feed it twice to the LLM to generate a pair of responses. Annotate one as positive and the other as negative based on “human preference”.
- Train the LLM directly with the dataset of (2) with the following loss function:
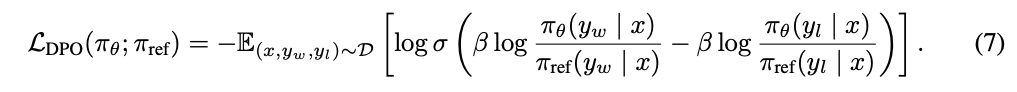 where y_w and y_l are the positive and negative samples. The denominator in loss function (\phi_ref), keeps the model to not diverge too much from the original model weights.
where y_w and y_l are the positive and negative samples. The denominator in loss function (\phi_ref), keeps the model to not diverge too much from the original model weights.

The following figure (taken from AI Coffee Break with Letitia [2]) illustrates the difference between RLHF and DPO.

A side note
Can this loss function be applied to a model that uses the triplet loss? It might provide better performance since it’s the closed form of the optimal policy.
Resource
[1] DPO paper