TL;DR
Machine learning models require a loss function to tune their parameters. Designing a loss function to reflect ambiguous human values poses a challenge, e.g., it’s not clear how to formulate a loss function to represent what is funny or ethical. To this end, a reward model is trained via human feedback. This reward model takes the model’s output and predicts a reward score that is then used by the model to optimize its parameters.
Method
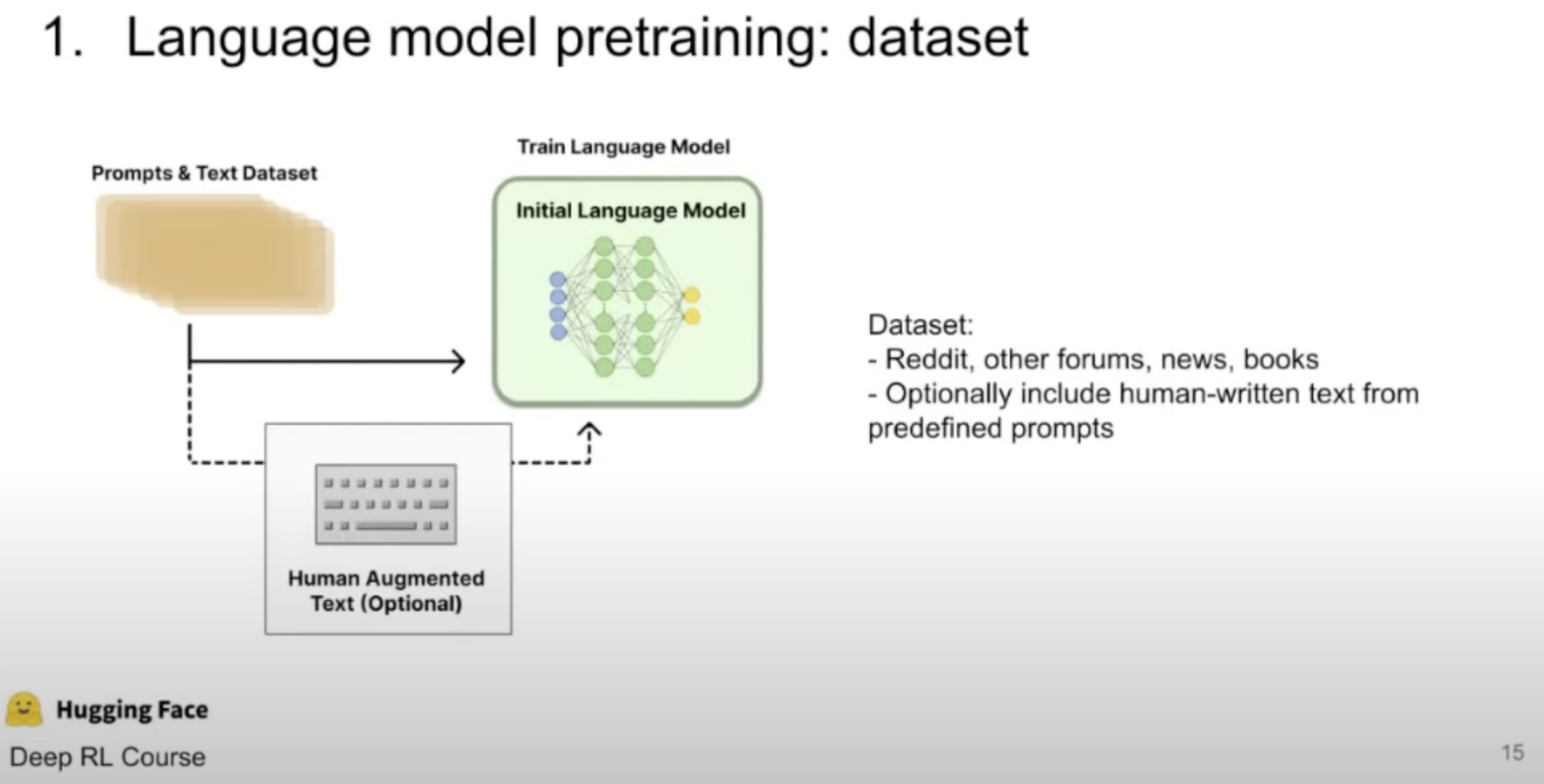
Pre-trained model. We are given a pre-trained model. In the RLHF context, this model was trained with a large dataset in unsupervised manner (like next token prediction). This pre-trained model then might be fine-tuned on a labeled dataset like in the summarization task.
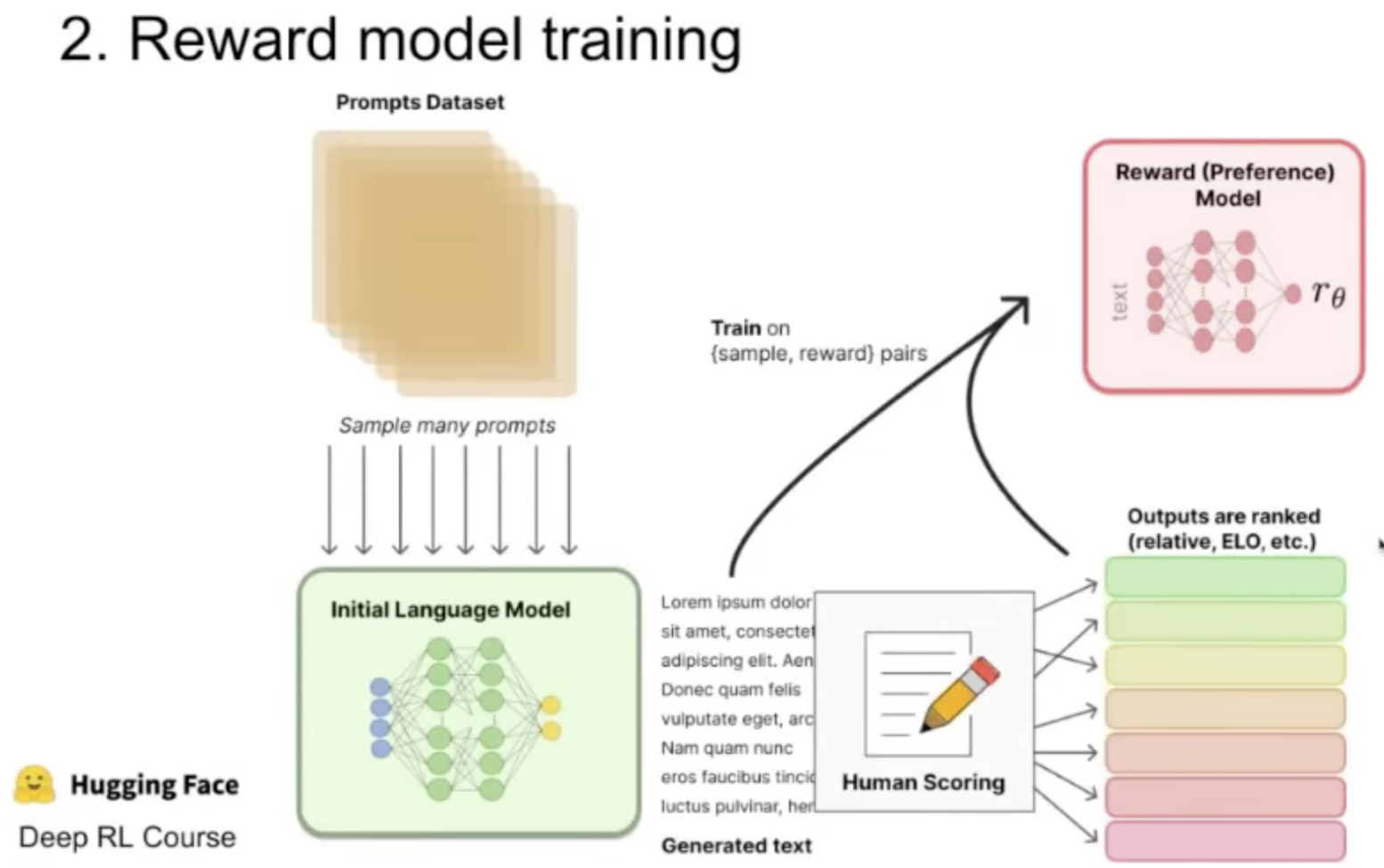
Reward model training. This stage includes:
- Sample many prompts and feed them to the model.
- Humans rank the outputs to create a ranking score. We might use multiple models such that the same prompts going through different models.
- A reward model is trained based on the human feedback of (c): Given text input, its output is a scalar.
Notice, this dataset is labeled and created specifically based on the pre-trained model. Therefore is much smaller than the original dataset.
- Fine-tune with Reinforcement Learning (RL). Here we train the model with the predictions of the reward model. However, we constrain it (the fined-tuned RLHF model) to be not too far from the original weights with the KL-divergence loss. Lastly, we plug the reward to the RL optimizer. RL update e.g. PPO.
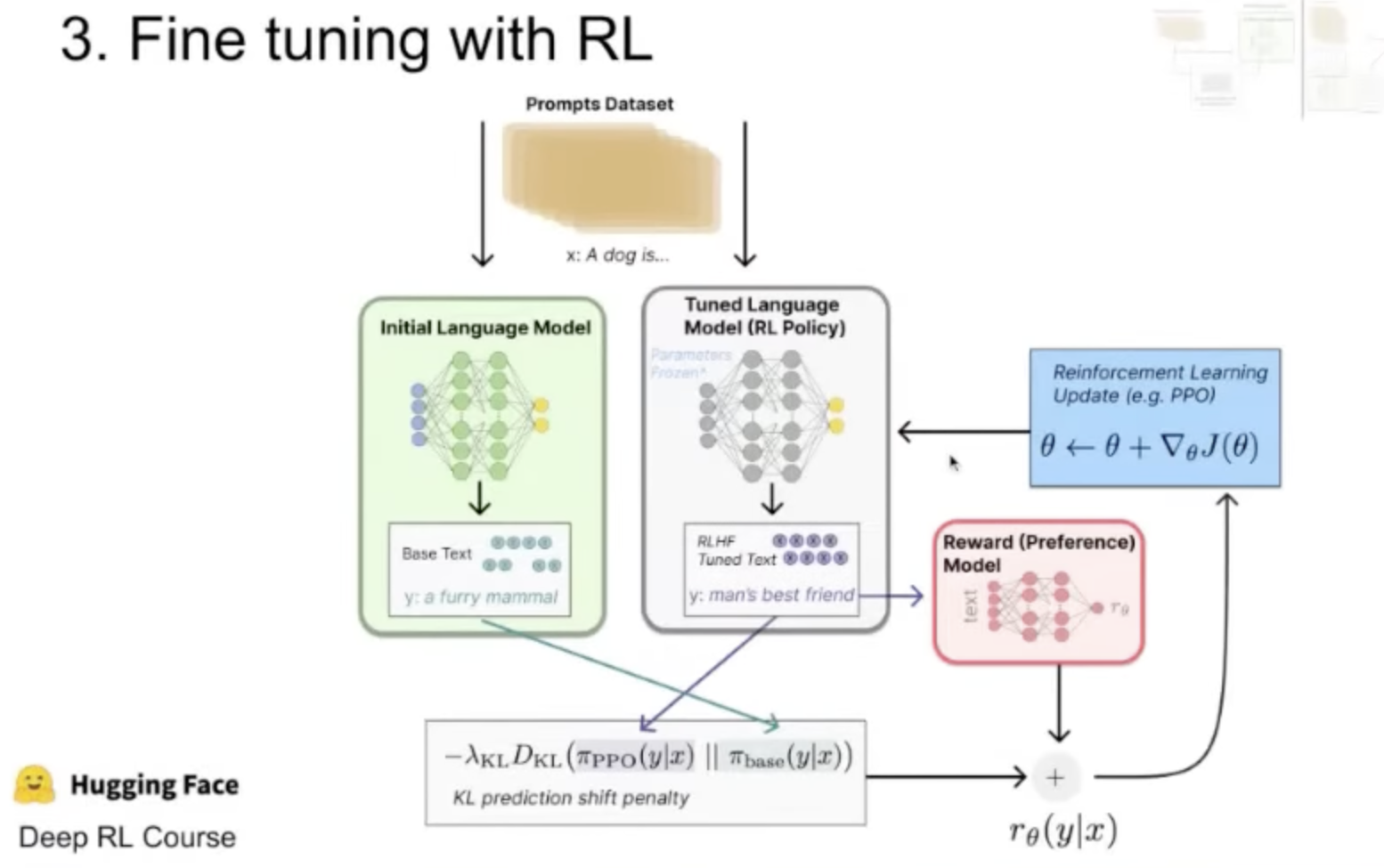
A side note: Why using a reward model and not training the base model with human feedback directly? Usually, the base model is trained in unsupervised way (like next token prediction) on a large amount of data. Annotating this data with human feedback is expensive.
Limitations
This approach is difficult to use: on one hand with don’t one the model to divergent too much from the original model to not loos performance. On the other hand, to better reflect human feedback, the model needs to be trained on the reward score.
Resource
Reinforcement Learning from Human Feedback: From Zero to chatGPT