TL;DR
A new video representation by (i) a canonical image that aggregates the static contents and (ii) a temporal deformation field that reconstructs the video frames when applied to the static image.

Problem statements
Video processing comes at a high cost,and naively processing frames results in poor cross-frame consistency.
Method
High level objective. The proposed representations should have the following characteristics:
- Fitting capability for faithful video reconstruction.
- Semantic correctness of the canonical image to ensure the performance of image processing algorithms.
- Smoothness of the deformation field to guarantee temporal consistency and correct propagation.
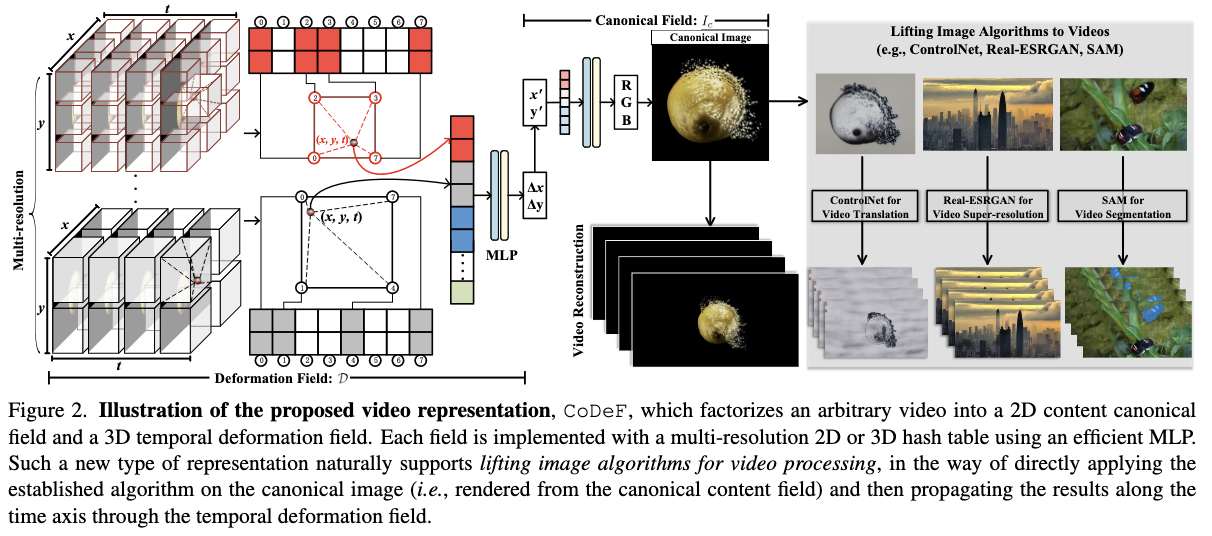
Model. The model consists of a 2D hash-based canonical image field (C) coupled with a 3D hash-based temporal deformation field (D). An arbitrary position x in the t-th frame is first encoded by a 3D hash encoding function γ3D(x, t) to get high-dimension multi-resolution features. Then a tiny MLP maps the embedded features its corresponding position in canonical field (γ3D(x, t)) → x′.
Multiple deformation files. For videos featuring large occlusions, additional layers corresponding to multiple content deformation fields are used. These layers would be defined based on semantic segmentation (using the Segment-Anything-track method). Each semantic layer is associated with a mask. For each layer, a group of canonical fields and deformation fields represent the separate motion of different objects.
Training loss. The representation is trained by minimizing the L2 loss between the ground truth color and the predicted color for a given coordinate in addition to multiple regularization terms.
Limitations
The model needs to be train per a specific video. The training duration is approximately 5 minutes for 100 video frames (3 second video).
Unable to manage diverse videos that cannot be represented by a canonical image.
Resource
https://arxiv.org/abs/2305.16311 published in ECCV 2022.
A youtube video that shows how to run the code
Computing methods:
- Yoni Kasten, Dolev Ofri, Oliver Wang, and Tali Dekel. Layered neural atlases for consistent video editing. ACM Trans. Graph., 2021.
- Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In Eur. Conf. Comput. Vis., 2020.
This method utilizes:
- Yangming Cheng, Liulei Li, Yuanyou Xu, Xiaodi Li, Zongxin Yang, Wenguan Wang, and Yi Yang. Segment and track anything, 2023.